Filters, Waves and Spectra

Department of Economics, University of Leciceter, Leicester LE1 7RH, UK
Econometrics 2018, 6(3), 35; https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics6030035
Submission received: 17 March 2018
/
Revised: 15 July 2018
/
Accepted: 17 July 2018
/
Published: 27 July 2018
(This article belongs to the Special Issue Filtering)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Econometric analysis requires filtering techniques that are adapted to cater to data sequences that are short and that have strong trends. Whereas the economists have tended to conduct their analyses in the time domain, the engineers have emphasised the frequency domain. This paper places its emphasis in the frequency domain; and it shows how the frequency-domain methods can be adapted to cater to short trended sequences. Working in the frequency domain allows an unrestricted choice to be made of the frequency response of a filter. It also requires that the data should be free of trends. Methods for extracting the trends prior to filtering and for restoring them thereafter are described.
1. Introduction
Techniques of filtering have been employed in econometric analysis since the inception of the subject in the second quarter of the 20th century. Major advances in the linear filtering theory were achieved, subsequently, by engineers and mathematicians during and after the Second World War. These developments were largely in aid of military technology.
The notable contributions of Wiener [1941] (1949) and of Kolmogorov (1941a,1941b) were addressed, originally, to the problem of anti-aircraft fire control (see Guerlac 1947). The work of the Radar Laboratory of MIT (the Rad Lab), which operated from 1940 to 1945, formed the basis of the textbooks on signal processing that began to be published in the late 1950s; and its influence is still discernible in modern texts.
As soon as security permitted, the wartime work of the Rad Lab was published in 28 volumes by the McGraw-Hill Publishing Co. (New York), beginning with the survey volume of Ridenour (1947) and culminating in the combined index of Henney (1953).
These advances were succeeded by a revolution in digital communications, which has involved the conversion of continuous-time formulations to their discrete-time counterparts. The developments were assisted by the discovery of a variety of computational algorithms, which have come to be known collectively as the fast Fourier transform or as the FFT. A major contribution was the algorithm of Cooley and Tukey (1965).
The mature state of the art in digital signal processing was summarised in the texts of Rabiner and Gold (1975) and of Oppenheim and Schafer (1975) and in the survey paper of Kailath (1974).
In the process of the digital revolution, the theory of signal processing has become more appropriate to econometric applications that depend on sampled data. Nevertheless, it is only recently that economists have begun to pay attention to the engineering literature; and their outlook remains significantly different from that of the engineers.
The engineering literature is concerned, primarily, with the frequency characteristics of the signals that are the subjects of the analysis. A frequency-domain analysis presupposes that the signals can be represented by linear combinations of trigonometric or complex exponential functions. These are perpetual periodic or circular functions. Therefore, the resulting theory is appropriate to stationary signals of an indefinite duration that are devoid of trends.
Economists, by contrast, are concerned, primarily, with data sequences of a limited duration that often manifest significant trends both in their levels and in the amplitudes of their fluctuations. In addition, the economists have tended to conduct their analyses in the time domain as opposed to the frequency domain. The notable exceptions have been the books of Granger and Hatanaka (1964) and of Fishman (1969). Moreover, the adaptation of the engineering theory to the circumstances of trended data sequences of limited duration has continued to be problematic.
This paper will begin by expounding a frequency-domain approach that relies on the concepts of Fourier analysis. It will demonstrate the connection between the discrete-time and continuous-time formulations and it will show that, notwithstanding the fixity of the sampling intervals in econometric data, the rate of sampling can be varied whenever it is possible to reconstitute the continuous trajectory of a signal from its sampled values.
By resampling the data at a lesser rate, the spectral support of a data component of limited frequency can be expanded so that it extends over the full Nyquist interval that runs from zero frequency to a frequency of radians per sampling interval. This should enable the component to be represented successfully by an autoregressive moving-average (ARMA) model.
The paper will proceed to show how a variety of filters that have been conceived in the time domain can be usefully implemented by conducting the essential computations in the frequency domain. Working in the frequency domain will allow an unrestricted choice of the frequency response of the filter.
2. Sinc Function Interpolation and the Sampling Theorem
The data that are available for time-series analysis are usually obtained by sampling continuous processes at regular intervals. The observable frequencies are limited to a maximum of radians per sampling interval, which is described as the Nyquist frequency. Frequencies in excess of this value are confounded with their aliases the lie within the Nyquist interval of .
2.1. Aliasing
To illustrate the effect of aliasing, we may consider the case of a pure cosine wave of unit amplitude and zero phase displacement of which the frequency is , so that . Let , which is to say that the samples are taken at unit intervals. Then,
which indicates that and , which is its alias, are observationally equivalent. The trigonometric functions are liable to be expressed in terms of complex exponential functions that have both positive and negative frequencies (see Equation (A1) in Appendix A).
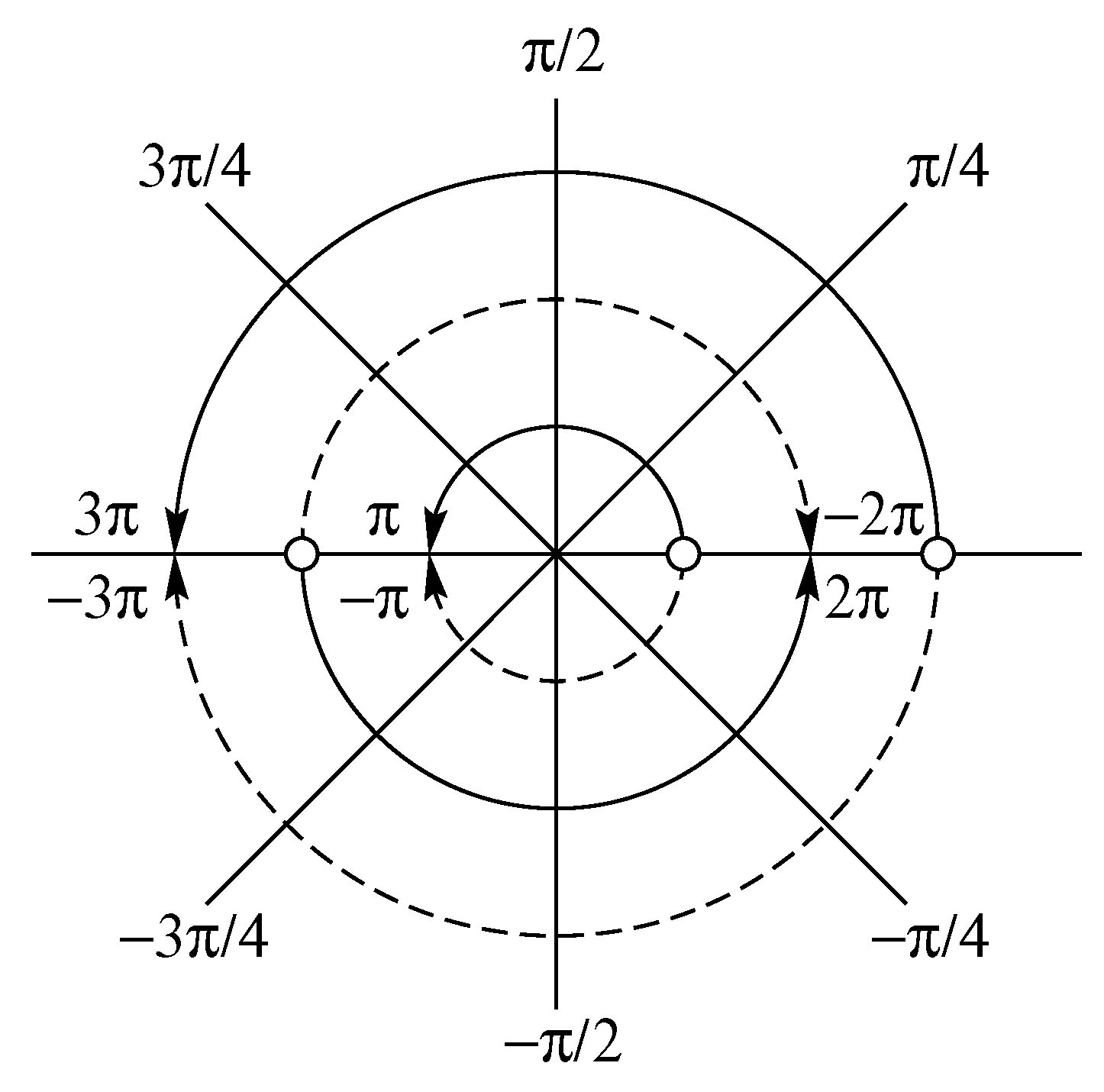
Within the sampled data, frequencies that lie beyond the Nyquist interval are mapped into that interval by a process of circular wrapping. The interval corresponds to the angles made with the positive horizontal axis by the radius of a circle. For positive frequencies , the segment is wrapped around the circle in an anticlockwise sense. The end of the wrapped segment marks the tip of a radius of which the angle is the alias of . For a negative frequencies , the segment is wrapped around the circle in a clockwise sense.
The effect, for a positive frequency , is that a multiple k of , which is the number of windings rounded to the nearest integer, is subtracted such that , whereas, for negative frequencies, a multiple of is added to produce the same effect. The following formula maps from the angles to their aliases:
The calculation can be made via the diagram of Figure 1.
A continuous trajectory may be derived from a sequence , sampled from a continuous absolutely integrable signal , by a method of kernel interpolation. A kernel is a continuous unimodal function of which the (absolute) values diminish with the distance from its centre at and which integrates to unity. The discrete impulses of the sequence may be replaced by kernel or scaling functions of the appropriate scales, of which the overlapping ordinates are summed at every point on the real line. The interpolated continuous function is
2.2. The Sampling Theorem
The mathematically ideal way to interpolate the sequence is to use the so-called sinc function kernel. A sinc function centred on k, which is the (inverse) Fourier transform of a rectangle in the frequency domain, is defined by
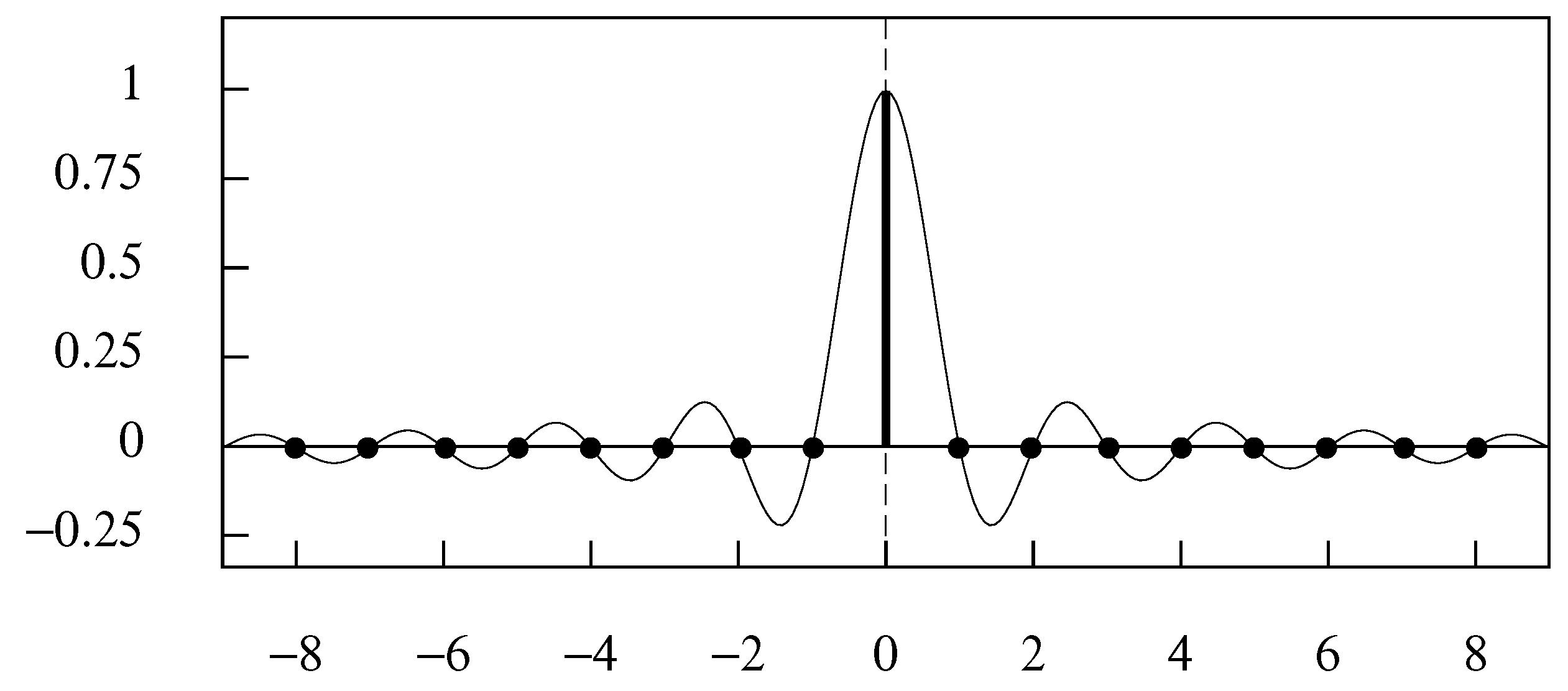
The conversion of the complex exponential functions on the LHS of the equation to the trigonometric function on the RHS depends on Euler’s equations, which are displayed in Appendix A, where an account of the Fourier transform is also to be found. This sinc function, which is represented in Figure 2, may also be described, in the context of a wavelets analysis, as a scaling function.
The sinc function has a limiting frequency of , and, provided that the frequencies in the original continuous function , from which a sequence has been sampled, are bounded by this value, then, as the Nyquist–Shannon sampling theorem indicates, a sinc-function interpolation will recover its trajectory exactly.
Let be an absolutely integrable continuous function defined on the real line. Then, the Fourier integral transform gives rise to the following expressions in the time domain and the frequency domain:
However, if the frequencies are bounded by the Nyquist value of , then there is a discrete-time Fourier transform
where is sampled at unit intervals from . Putting the RHS of (6) into the LHS and interchanging the order of integration and summation gives
where is the sinc function of (4).
It should be observed that , which is described as the discrete-time Fourier transform of the sequence , or, equally, as the spectrum of the sequence, is a continuous -periodic function of . Moreover, if the sequence is real-valued, then will be distributed symmetrically around zero in the interval , which enables the function to be represented by its values over the interval , which is the usual recourse.
The sampling theorem is attributable to several people, but it is most commonly attributed to Shannon (1949a, 1949b), albeit that Nyquist (1928) discovered the essential results at an earlier date.
Equation (7) of the Nyquist–Shannon sampling theorem represents an essential theoretical result, but it does not correspond to a practical way of creating a continuous trajectory from a finite sequence of values. The difficulty arises from the fact that is a doubly-infinite sequence and from the fact that each of the sinc function kernels is supported on the entire of the real line .
To interpolate a continuous function through a finite sequence of T equally spaced elements, the sinc function must be replaced by the Dirichlet kernel, which would result from wrapping the sinc function around a circle of circumference T and adding the overlying ordinates. However, an interpolation by Dirichlet kernels is equivalent to an ordinary Fourier interpolation (i.e., an interpolation via a Fourier synthesis). This is demonstrated in Section 4.5.
2.3. Orthogonal Bases and Wavelets
The sinc function is symmetric and idempotent such that
The latter follows from the fact that the unit rectangle on , which is the counterpart of the sinc function in the frequency domain, is unaltered when squared, and from the fact that a modulation in the frequency domain—in this case a squaring—corresponds to a convolution in the time domain.
The two properties of (8) imply that is its own autocovariance function. Therefore, the condition that for , which is manifest in Figure 2, implies that the sequence constitutes an orthogonal basis for the set of all functions bounded in frequency by the Nyquist value of radians per unit (sampling) interval.
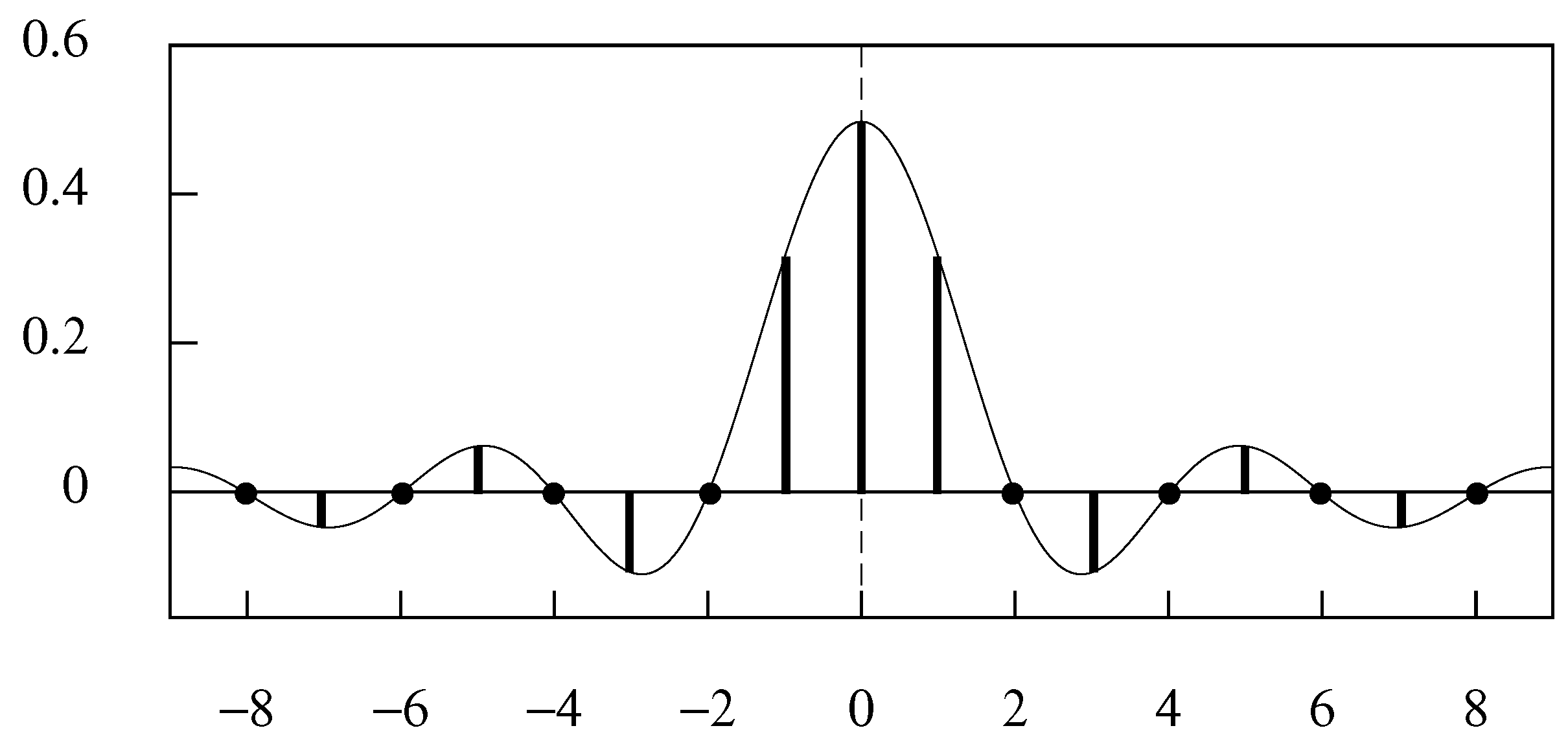
The sinc function kernel of Equation (4) is supported on the Nyquist frequency interval . A sinc function with a lesser frequency content can be used to create a smoother trajectory. The sinc function that is bounded in frequency by and centred on is
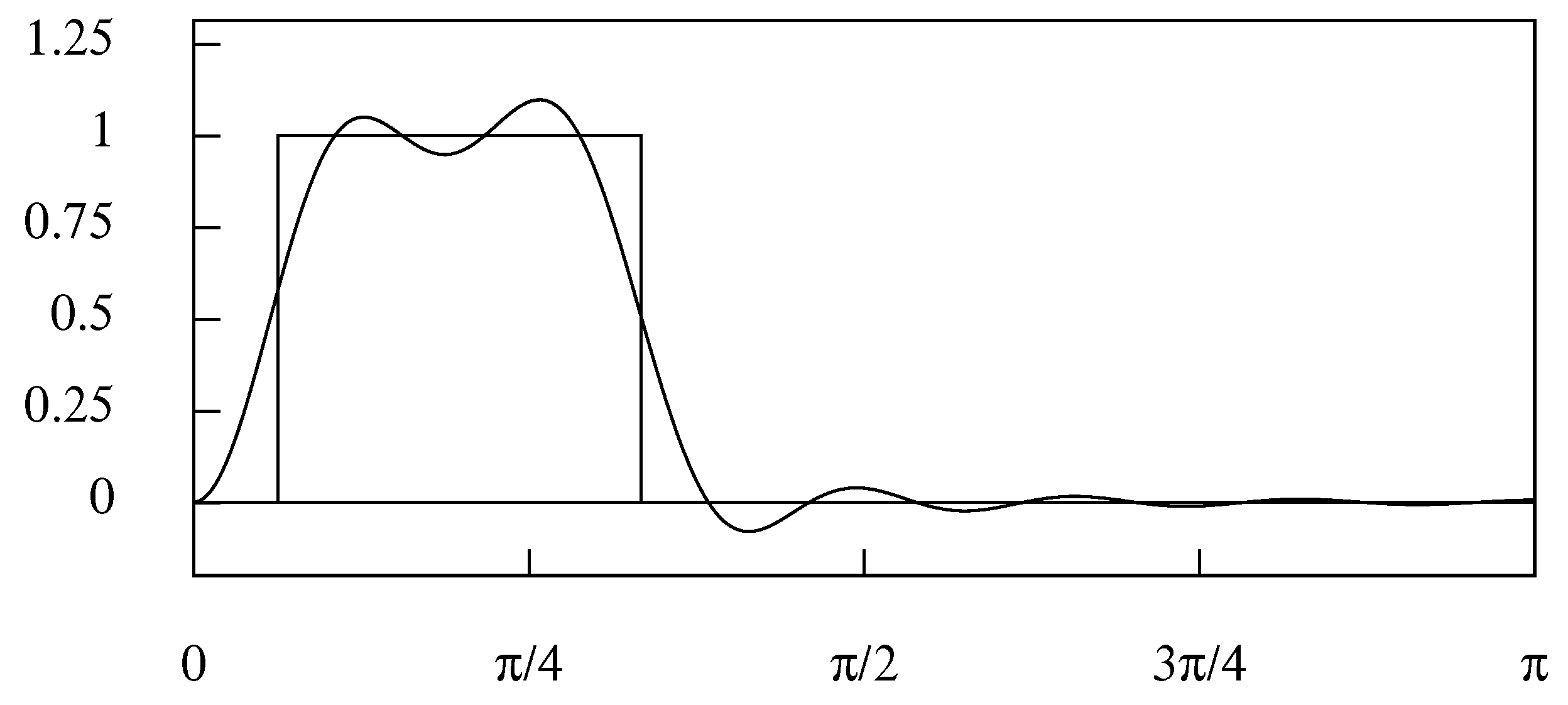
Figure 3 represents the function for which . It will be seen that for ; and it can be inferred that constitutes an orthogonal basis for the set of all functions bounded in frequency by radians.
A function that contains the low-frequency content of , and which is therefore smoother, can be obtained by associating the half-frequency sinc functions to the elements of the sampled sequence to form
The smoothing effect is by dint of the way in which the value of each discrete-time ordinate is dispersed more widely than in the case of the sinc function of (4), wherein . To produce a smooth approximation to , it would be necessary to multiply the functions by 2 to ensure that they integrate to unity.
The complete information content of the function will be conveyed by the sequence sampled from the continuous trajectory, less frequently, at intervals of two units. Whereas the discrete Fourier transform of the sequence will be nonzero only over the half interval , that of the subsampled sequence , which is , is liable to be nonzero over the entire Nyquist interval. Thus, whereas subsampling will compress the sequence, its effect in frequency-domain is to distend the spectrum.
The sinc function can be expressed in terms of the functions , which provide an orthogonal basis for the set of functions bounded in frequency by . Thus,
where the coefficients are sampled from the function at unit intervals. The same relationship prevails between the functions and , which are supported on the frequency intervals and , respectively.
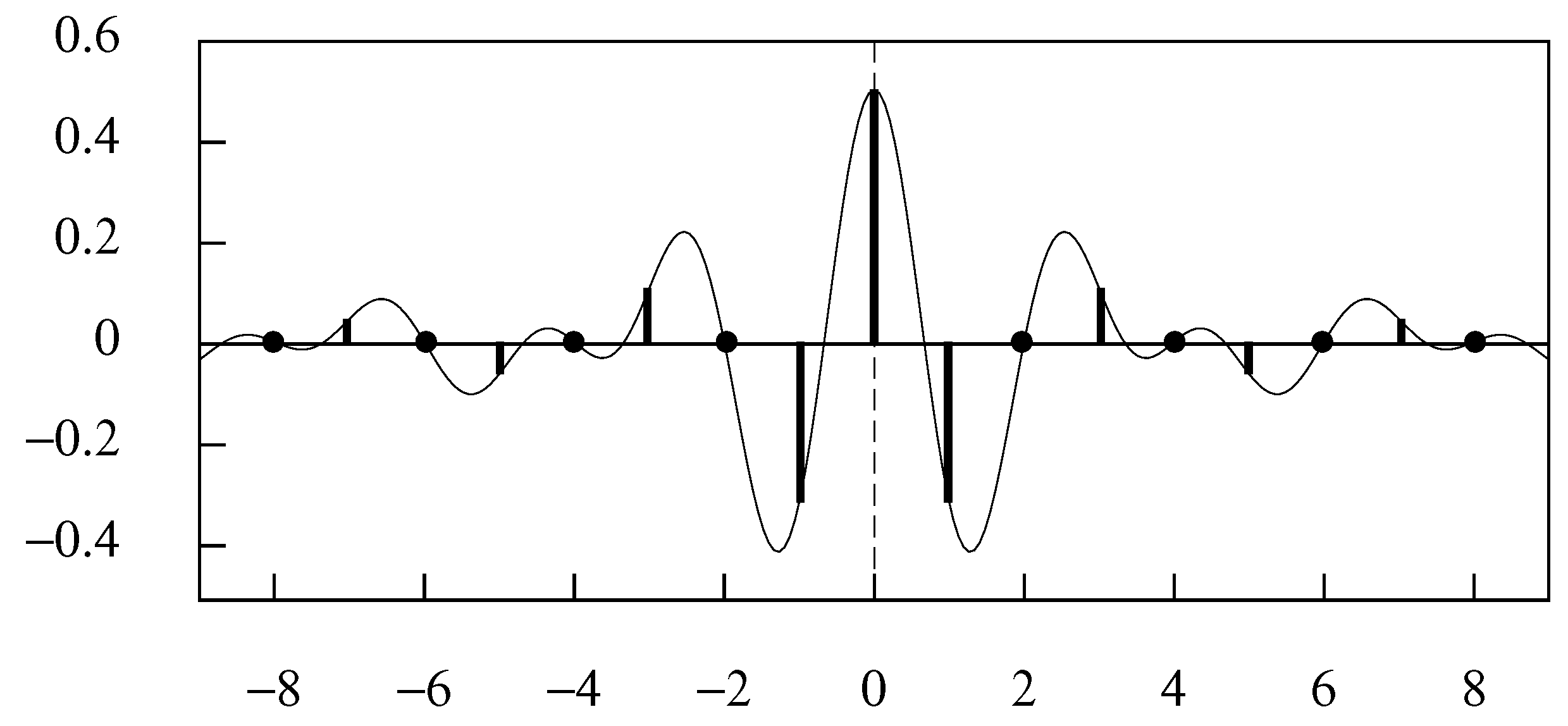
The sinc function is accompanied by a complementary wavelet function defined on the interval , if one is considering the constituent complex exponential functions, or on the interval , if one is considering the trigonometric functions. The interval contains the angles subtended by the left half of the unit circle centred on the origin of the complex plane. The wavelet is shown in Figure 4.
The wavelet can be expressed variously as
The final expression represents the effect of shifting the scaling function in frequency by radians, via a method of cosine modulation, whereby the frequency interval , which supports the scaling function, becomes the interval , which is the support of the wavelet. The effect of multiplying the sinc function by is to shift two copies of its frequency-domain rectangle from its centre at zero to centres of and , whereafter the copies are added and divided by 2. A generalised method of cosine modulation is described in Section 4.1.
The decomposition of the original sinc function at level 0 into a scaling function and a wavelet at level 1 represent the first stage of a dyadic decomposition that can be applied to the succession of scaling functions of diminishing frequency content and of increasing dispersion, so as to create an orthogonal wavelets basis.
The wavelet at level 1 can be expressed as a linear combination of the scaling functions at level 0. Thus, there is
which is similar to Equation (11). The scaling function and the wavelet at any level j are mutually orthogonal, since their frequency bands and are virtually disjoint.
There are other scaling functions and their accompanying wavelets that can give rise to orthogonal dyadic decompositions. These functions tend to benefit from having finite supports in the time domain. However, a reduction of the dispersion in the time domain leads to an increased dispersion in the frequency domain, with the effect that the functions are no longer confined to their designated frequency bands.
A fuller account of wavelets analysis is available in many texts, amongst which the coupled volumes of Vetterli et al. (2014) and Kovačević et al. (2013), which are available on the web, give a comprehensive account of the theory. Another source at a high level of mathematical sophistication is the volume of Mallat (1998).
Wavelets analysis has many practical applications, of which the statistical applications are touched on in the paper of Abramovich et al. (2000). From the present point of view, wavelets analysis can be regarded as a synthesis of the discrete-time and the continuous-time analyses of signals.
3. Linear Filters
Let be a sequence sampled at unit intervals from the kernel function . Then, the sequence , sampled from the trajectory of (3), can be generated by a discrete-time convolution such that
This equation describes an operation of linear filtering applied to the sequence .
The first expression on the RHS of (14), which corresponds to the expression of Equation (3) for kernel function interpolation, depicts a dispersion over time of the data ordinates. The second expression, which is the more usual one, depicts the operation of filtering as a matter of forming a moving average of the data.
In demonstrating the effects of the filter, it is helpful to consider the z-transforms of the various sequences. The data sequence is converted to a power series by associating to each element and by summing the resulting sequence. Thus,
The convolution operation of Equation (14) becomes an operation of polynomial multiplication in Equation (15). The z-transform of the filter coefficients is liable to be described as the transfer function of the filter.
The sequence of the filter coefficients is also described as the impulse response of the filter, since can be obtained from the equation when , is an impulse sequence that has a unit where and zeros elsewhere.
3.1. The Gain and Phase Effects
The frequency response of the filter, which is a continuous function of the frequency , is the result of mapping the complex exponential sequence through the filter defined by the coefficients to give
The complex-valued frequency response function is
On the RHS, there is the gain or amplification effect , which corresponds to the modulus of the complex function, and the phase or time-delay effect , which corresponds to its argument. A symmetric filter, with for all j, will have no phase effect.
It is convenient to represent the frequency response and the squared gain of the filter by
3.2. A Classical Econometric Filter
The econometric filters that have predominated until recently have been conceived as smoothing operations to be applied directly to the sampled data. An example is provided by the filters of Henderson (1916, 1924) that have been incorporated in the X-11 program, which is still commonly used in the seasonal adjustment of econometric data.
Detailed accounts of the filters have been provided by Kenny and Durbin (1982) and by Pollock (2009), and the X-11 program has been described in detail by Ladiray and Quenneville (2001).
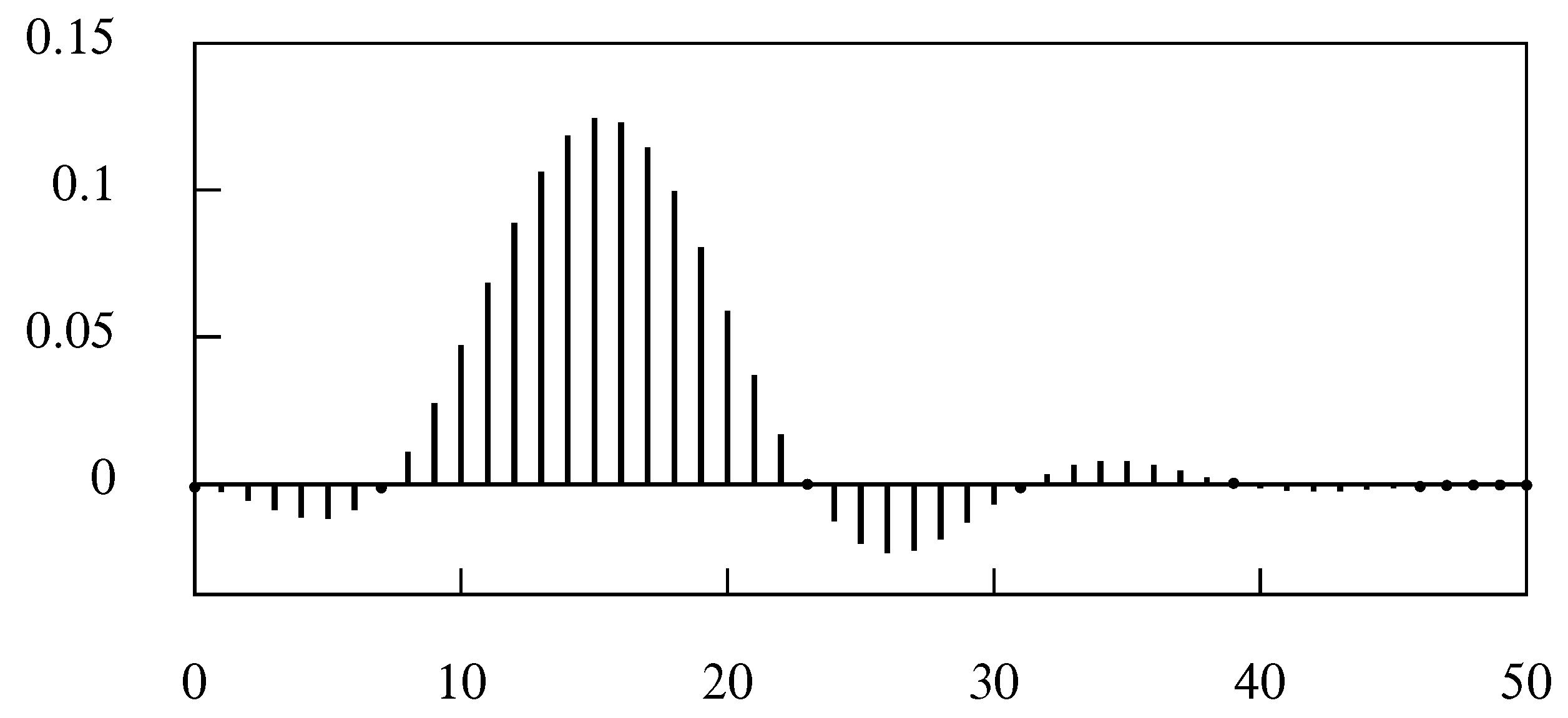
These filters, which are realised as finite-order moving averages, apply a cubic polynomial interpolation to subsets of the data that fall within a window that moves step-by-step through the data. The value of the smoothed sequence that replaces the data value is the central value of the fitted polynomial. The essential property of the filter is that it will transmit a cubic time trend without alteration.
Figure 5 represents the coefficients of the symmetric Henderson moving-average filter of 23 points. Figure 6, which represents the frequency response function of the filter, shows a gradual transition from the pass band, which preserves the sinusoidal (or complex exponential) elements of a stationary process, to the stop band, which attenuates them and which ultimately nullifies them.
A symmetric moving-average filter that spans of data points, and which looks equally forwards and backwards in time, encounters a problem when it reaches the ends of the data. Unless sets of m extra-sample points are added at both ends, the filter cannot process the first and the last m data points.
When the filter is applied to a mean-zero stationary process, it is reasonable to represent the extra-sample elements by their zero-valued expectations. This is not an appropriate recourse when the filter is applied directly to trended data with values that are remote from zero.
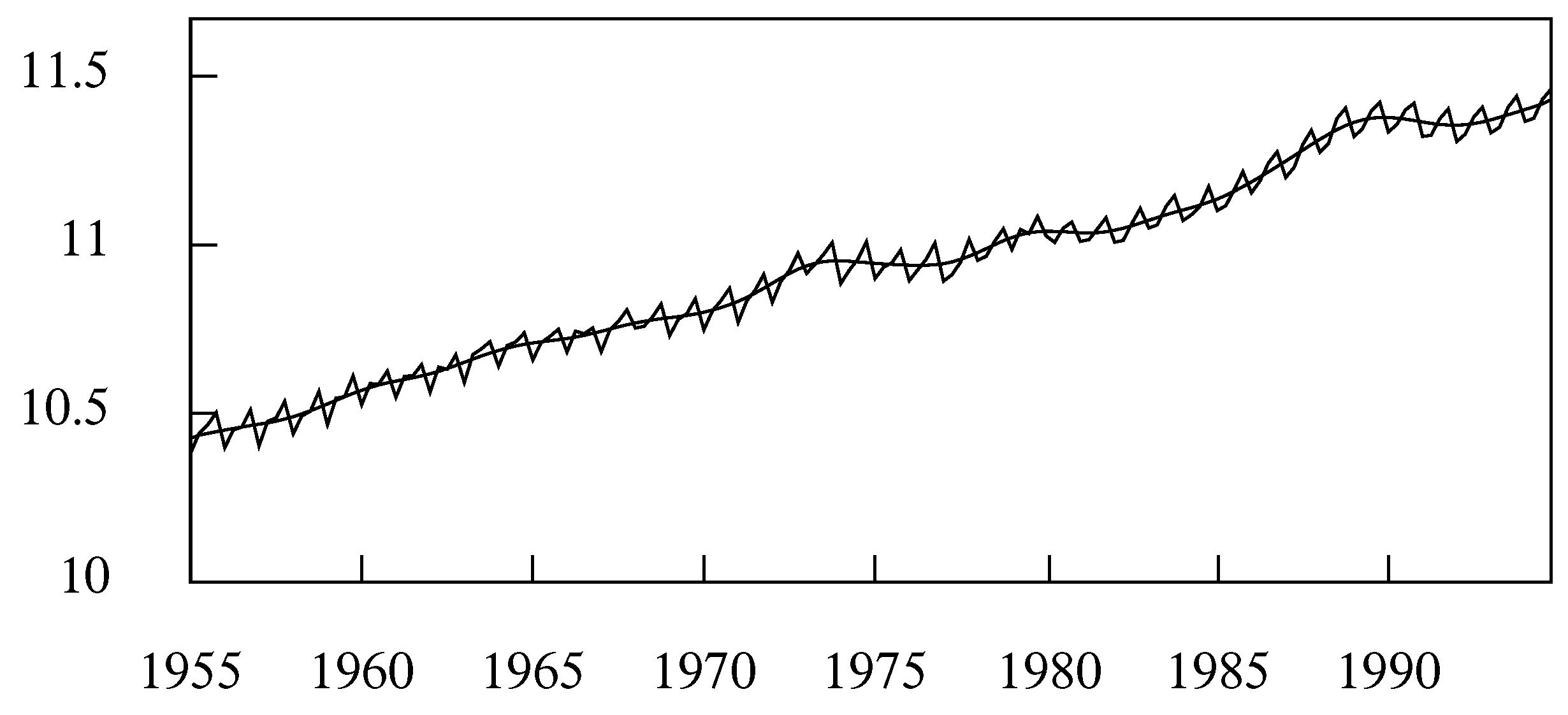
Since the Henderson filter is commonly applied directly to trended econometric data, such as are seen in Figure 7, it is necessary to deal effectively with the end-of-sample problem. Either the data must be extrapolated, or else the filter must be shortened so that it does not extend beyond the sample as it approaches the ends. In that case, the filter coefficients must be modified as the filter is collapsed.
As Wallis (1981) has shown, a procedure based on a time-invariant filter that overcomes the end-of-sample problem by using extrapolations based on sample values can be replaced by an equivalent procedure that applies a time-varying filter to points within the sample.
Various methods for extrapolating the sample and the equivalent means of modifying the filter coefficients have been proposed for the Henderson filters. Some of these have been cryptic and unexplained, as was the method proposed by Shiskin et al. (1967) for the filters within the X-11 program.
Since the Henderson filter is based on a cubic polynomial interpolation, it is natural to use a cubic function as the means of extrapolation. This approach has been adopted by Kenney and Durbin, who propounded an equivalent method for adapting the filter coefficients.
However, the method of adapting the coefficients that has been deployed in the X-11 program and its variants uses a linear extrapolation. The logic of that method has been uncovered by Doherty (2001), who has referenced the unpublished papers of Musgrave (1964a, 1964b) and of Laniel (1986) (see also Gray and Thomson (2002) for a discourse on the end-of-sample problem).
An alternative approach to constructing a filter is to define an appropriate frequency response and then to infer the coefficients of the corresponding filter to be applied in the time domain via a convolution with the data. However, it is also possible to conduct the filtering operation entirely in the frequency domain. This entails translating the data to the frequency domain and then translating them back to the time domain, once they have been processed.
In order to apply the frequency-domain methods, the data, which are treated as a circular sequence, must be devoid of trends. Therefore, methods are required for removing the trends from the data and for restoring the trends once the data have been filtered. Such methods will be described in Section 6. The need for complicated methods of data extrapolation that follow the trends in the data is alleviated in this approach.
4. The Ideal Filters
There may be a requirement for a more rapid transition from the pass band to the stop band of a filter than is available from the Henderson filter. Thus, for example, it has been the declared intention of Baxter and King (1999) to derive a filter that will isolate the components of an index of US GDP that have a cyclical duration of no less than six quarters (eighteen months) and of no more than 32 quarters (eight years). This prescription is due to a definition of the business cycle that was provided by Burns and Mitchell (1946).
Baxter and King sought to fulfill their requirement via a band pass filter that should, ideally, have instantaneous transitions at the two frequency values. In pursuit of such a filter, one may begin by defining an ideal low pass filter, which can be transformed to a band pass filter.
The ideal low pass filter with a positive-frequency cut-off point at is specified by the following periodic frequency response function, which has a period of and which is specified over the interval by
Within the interval , the sub interval is the pass band whilst the remainder is the stop band.
The coefficients of the low pass filter are given by the (inverse) Fourier transform of the periodic square wave:
The result for follows by simple integration. The result for follows from setting under the integral. Reference to Equation (9) shows that the coefficients are values sampled at unit intervals from the corresponding sinc function. This is illustrated in Figure 3 for the case where . The resulting coefficients constitute a so-called ideal half-band filter.
4.1. Frequency Shifting
An ideal band pass filter with a positive-frequency pass band on the interval is defined as follows:
The corresponding time-domain function is
The identity can be used, with and , in place of A and B, to show that
The centre of the pass band is , whereas is half its width. The cut-off points of the pass band are . The low pass prototype filter is , whereas affects the frequency shifting.
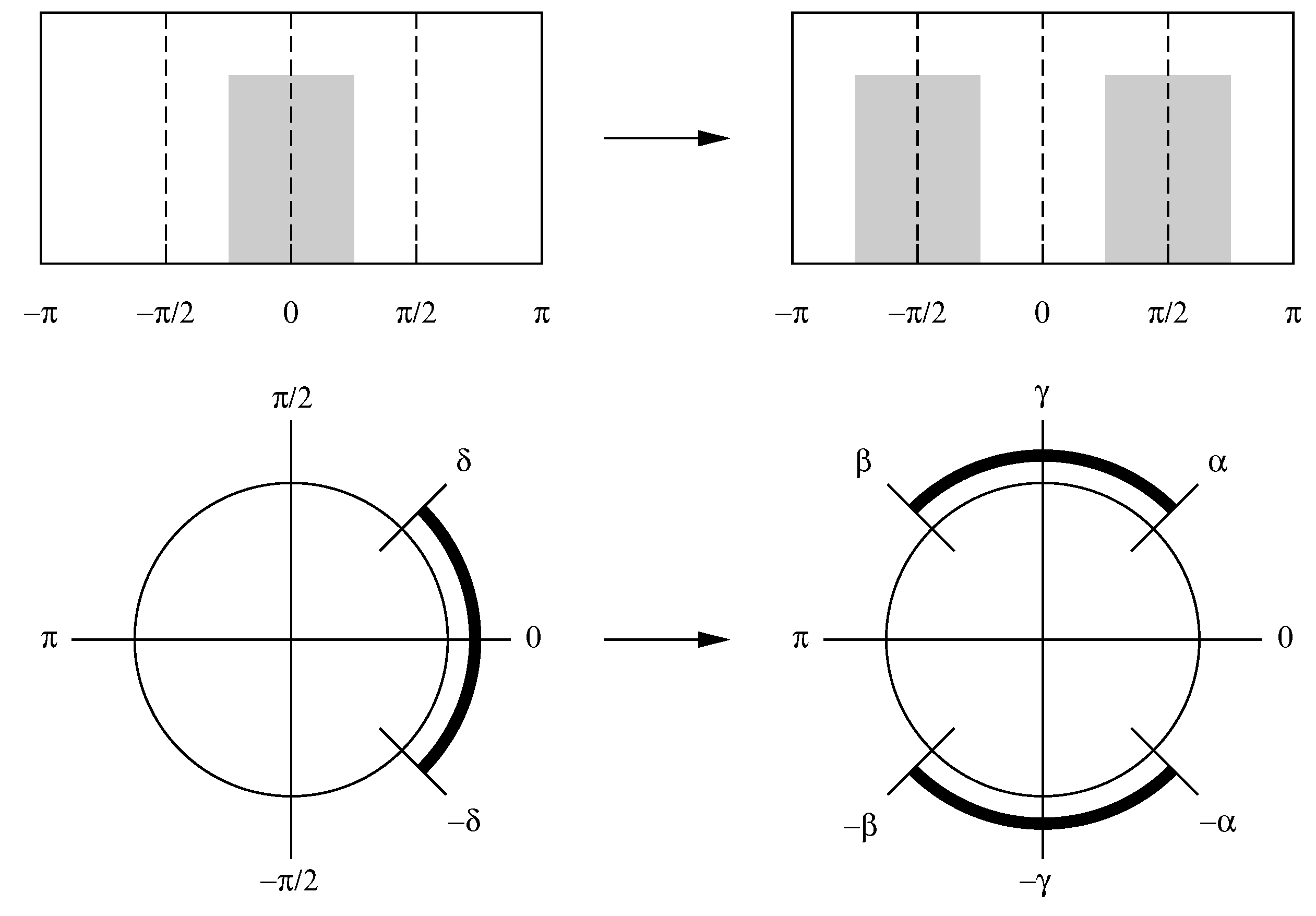
This effect of frequency shifting can be understood by recognising that . Thus, in Equation (23), two copies are made of the function , which has a pass band on the interval , and these are shifted so that their centres lie at and . Then, and . Figure 8 provides two representations of a frequency shift.
4.2. Truncating the Filter
A difficulty in applying the ideal filters that have been specified above lies in the fact that they entail an infinite number of coefficients. One way of addressing the problem is to truncate the filters by taking only a limited number of central coefficients to create what is described as a finite impulse-response (FIR) filter.
The coefficients of a band pass or a high pass filter must sum to zero, whereas the coefficients of a low pass filter must sum to unity. The coefficients of a truncated filter must be rescaled so as to meet these requirements. Constraining the coefficients to sum to zero ensures the the z-transform polynomial has a root of unity, such the . This implies that is a factor of the polynomial, which indicates that the filter incorporates a difference operator.
If the filter is symmetric, such that and, therefore, , then is also a factor. Therefore, has the combined factor , which indicates that the filter incorporates a twofold differencing operator. Such a filter is effective in reducing a linear trend to zero; and, therefore, it is applicable to the logarithms of econometric data sequences that have an underlying log-linear or exponential trend.
The effect of truncating the filter will be to create a frequency response that departs from the ideal square-wave response and that may allow a substantial leakage to occur in the stop band, whereby elements of the data are transmitted that should be blocked (see Figure 9).
A further problem with such filters is that they cannot reach the ends of a data sample. Thus, a symmetric filter of coefficients will be unable to process the first and the last m data values unless the sample is extrapolated. The matter has been raised in Section 3, but a full consideration of the problem will be deferred until Section 6.
4.3. The Ideal Filters in the Frequency Domain
One way of overcoming the problems of leakage is to work with the discrete Fourier transform of the finite data sequence , which gives rise to the sequence of Fourier ordinates:
In this context, both the data sequence and the sequence of Fourier ordinates are to be regarded as circular or periodic functions, with the former supported on the interval and the latter on the interval .
An ideal filter can be applied to a finite sample by operating on the ordinates of its Fourier transform. The ordinates that fall within the pass band are preserved while those that fall within the stop band are replaced by zeros. Then, the preserved ordinates are translated back into the time domain by the inverse transform.
An alternative and a less adept way of applying an ideal filter is to generate the time-domain coefficients of a circular filter that can be convoluted with the circularised data.
Consider a set of T frequency-domain ordinates sampled from a periodic square-wave or boxcar function, centred on , at the Fourier frequencies that fall within the interval . (For convenience, the frequency interval of the discrete Fourier transform can be replaced by the interval without affecting the analysis). If the cut-off points are at , then the ordinates of the sample will be
Since this is to be construed as a periodic function of period T, it follows that , which allows the (discrete) Fourier transform of the circular filter coefficients to be expressed as
This may be compared with the discrete-time Fourier transform that generates a doubly-infinite sequence of filter coefficients:
Since at the point , it follows, on comparing the RHS of (27) with that of (26), that
Thus, the circular coefficients would result from wrapping the infinite coefficient sequence around a circle of circumference T and adding the overlying ordinates.
This is impractical and, therefore, the circulant filter coefficients would be created, in practice, by applying a discrete Fourier transform to the corresponding frequency-domain ordinates to carry them into the time domain.
The formula for the wrapped circulant filter that fulfills the specification of (25) is
where .
In an alternative specification of the ideal filter, the cut-off points fall between Fourier frequencies. Then, the ordinates sampled from the frequency response function are
and the formula of the filter coefficients is
The coefficients of the Dirichlet kernels can be disposed symmetrically about the midpoint of the sequence of . The formulae of (29) and (31), which are (A25) and (A28) in the appendix A.3, are also to be found in an appendix to Pollock (2008).
4.4. The Band pass Specification
One might wish to construct a wrapped filter according to the more general band pass specification:
where and , and where it is assumed that T is even. For the ideal filter, this can be achieved by subtracting one filter from another to create
Here, is the width of the pass band (measured in terms of a number of sampled points) and is the index of its centre. The final expression follows from the identity . The expression can be interpreted as the result of shifting a low pass filter with a cut-off frequency at the point d so that its centre is moved from 0 to the point g. The technique of frequency shifting is not confined to the ideal frequency response. It can be applied to any frequency response function.
There is a prevalent notion that an ideal filter cannot be realised in practice, for the reason that to achieve an instant transition in the frequency response from a pass band to a stop band requires an infinite number of filter coefficients.
Although the frequency response of the finite-sample filter is defined only for T frequency points, it can be insightful to consider the function , where varies continuously in the interval Then, there is no requirement that the frequency response of the ideal filter should make an instant transition.
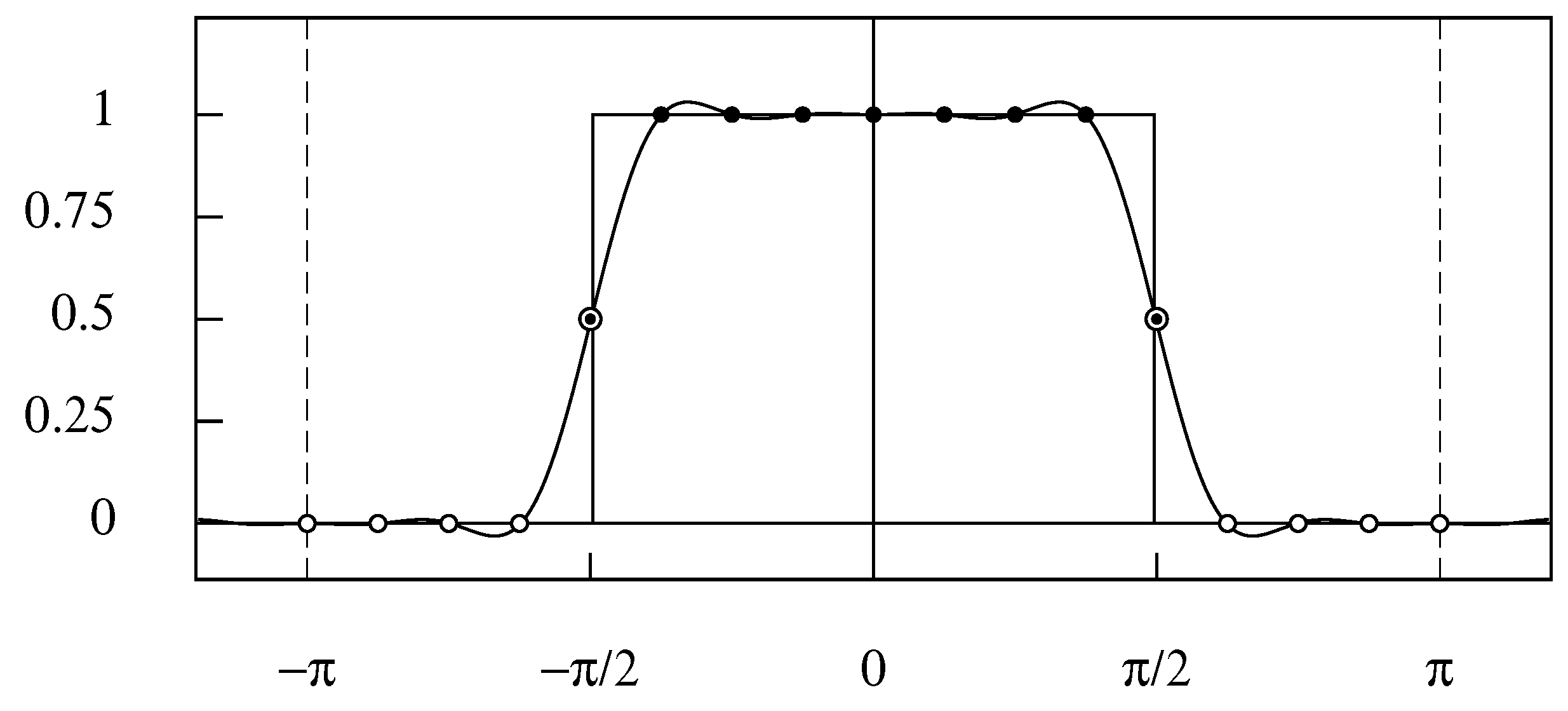
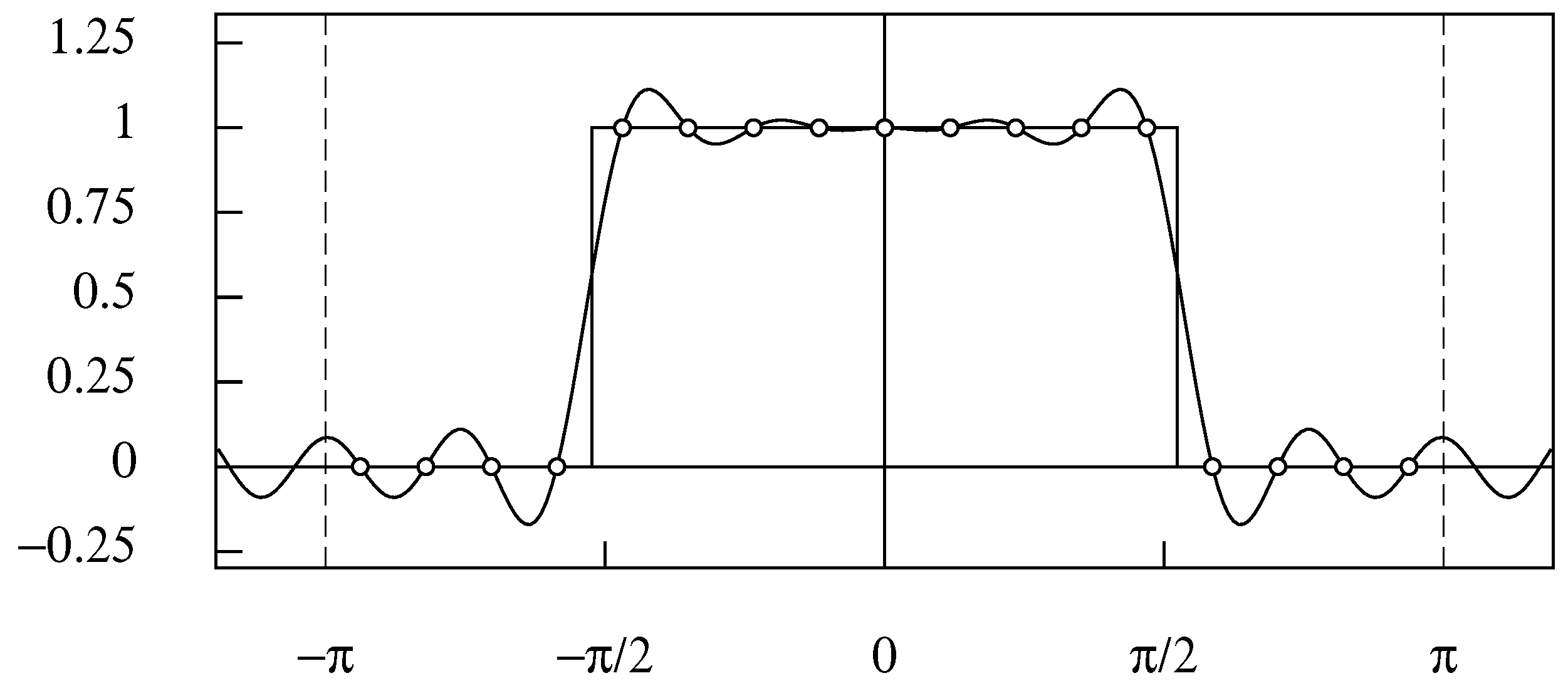
The matter can be elucidated by considering low pass half-band filter with a cut-off frequency of . In the case of an even sample size, where the midpoint of the transition is at the nominal cut-off point, the transitions occur within the interstices between that point and the adjacent frequency points on either side (see Figure 10). In the case of an odd sample size, the transition occurs between two adjacent frequency points (see Figure 11).
4.5. Interpolating a Finite Data Sequence
Dirichlet kernels provide a way of interpolating a finite data sequence. Consider again the discrete Fourier transform expressed as follows:
By putting the RHS of the latter into the LHS and commuting the two summations and allowing to vary continuously, and assuming that T is odd, we get
When T is odd, there is
which is the periodic Dirichlet Kernel supported on the Nyquist interval. When T is even, is provided by the formula of (29) with .
Equations (34) and (35) imply that a sinc function interpolation of a finite data sequence that employs a sequence of Dirichlet kernels is equivalent to an interpolation based on a Fourier synthesis. Thus, a simpler way of recovering a continuous trajectory from the sampled sequence is to allow the index t to vary continuously in the interval within the expression for the sequence that is provided by the discrete Fourier transform. The resulting trajectory is
where are the Fourier frequencies, which are placed at regular intervals running from zero to the Nyquist frequency of . Here, denotes the integer quotient of the division of T by 2.
The trigonometric functions and the complex exponential functions of (37) are connected via Euler’s equations (A1) and (A2) of Appendix A.1. In addition, and for . The coefficients are obtained by regressing the data on the ordinates of the trigonometric functions , where .
4.6. Resampling the Data
A Fourier interpolation, or the equivalent Dirichlet-kernel interpolation, can be employed whenever it is appropriate to lower the rate of the sampling of a data sequence.
The periodogram of the sequence may reveal that the continuous process from which the sampled data are derived has a frequency limit, expressed in terms of radians per sampling interval, of , which is below the Nyquist limit. This will be an impediment to fitting a linear time-series model, which presupposes that the spectrum of the sampled process is supported on the interval .
To ensure that the maximum frequency of the data coincides with the Nyquist frequency of radians per (unit) sample interval, one can regenerate the continuous trajectory by a Fourier synthesis. Thereafter, the interpolated trajectory can be resampled at the wider intervals of time units.
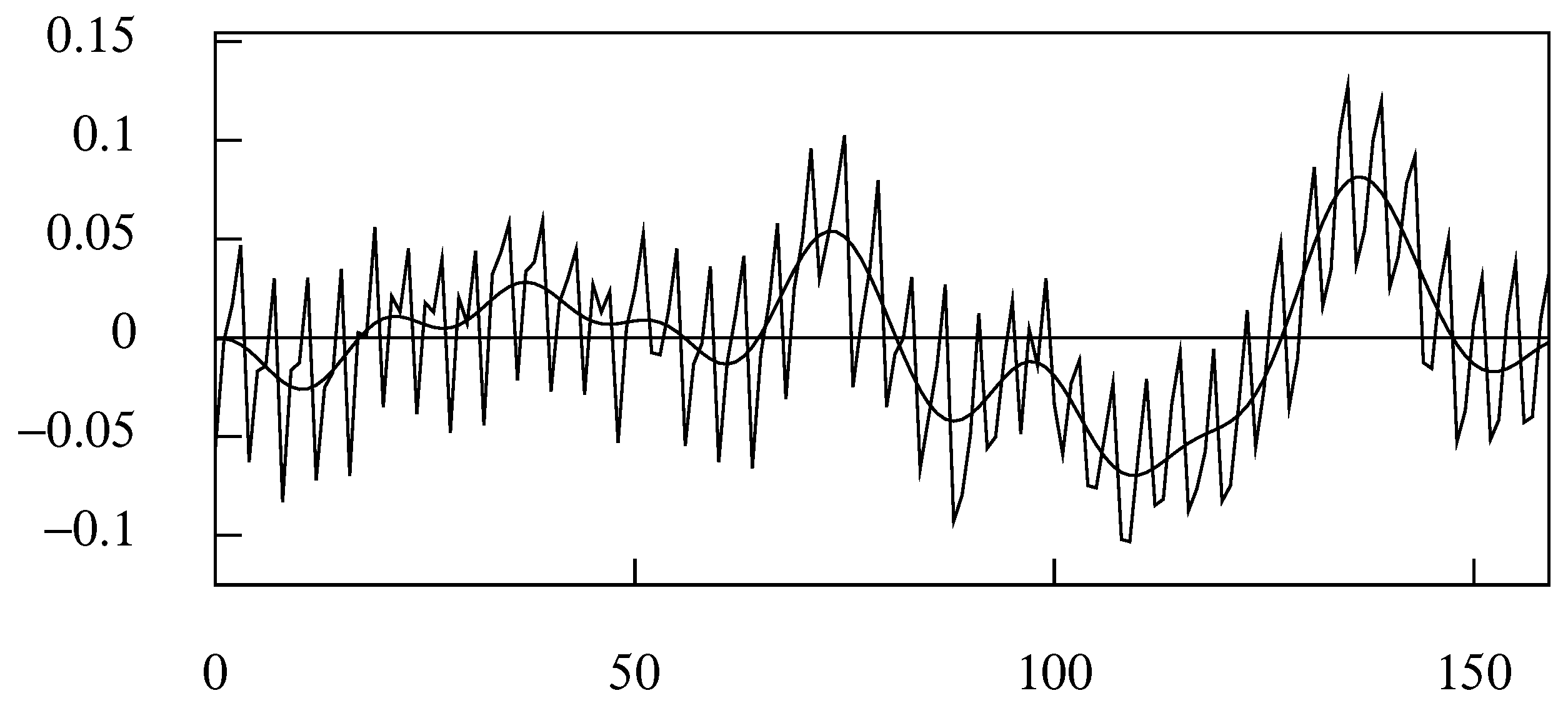
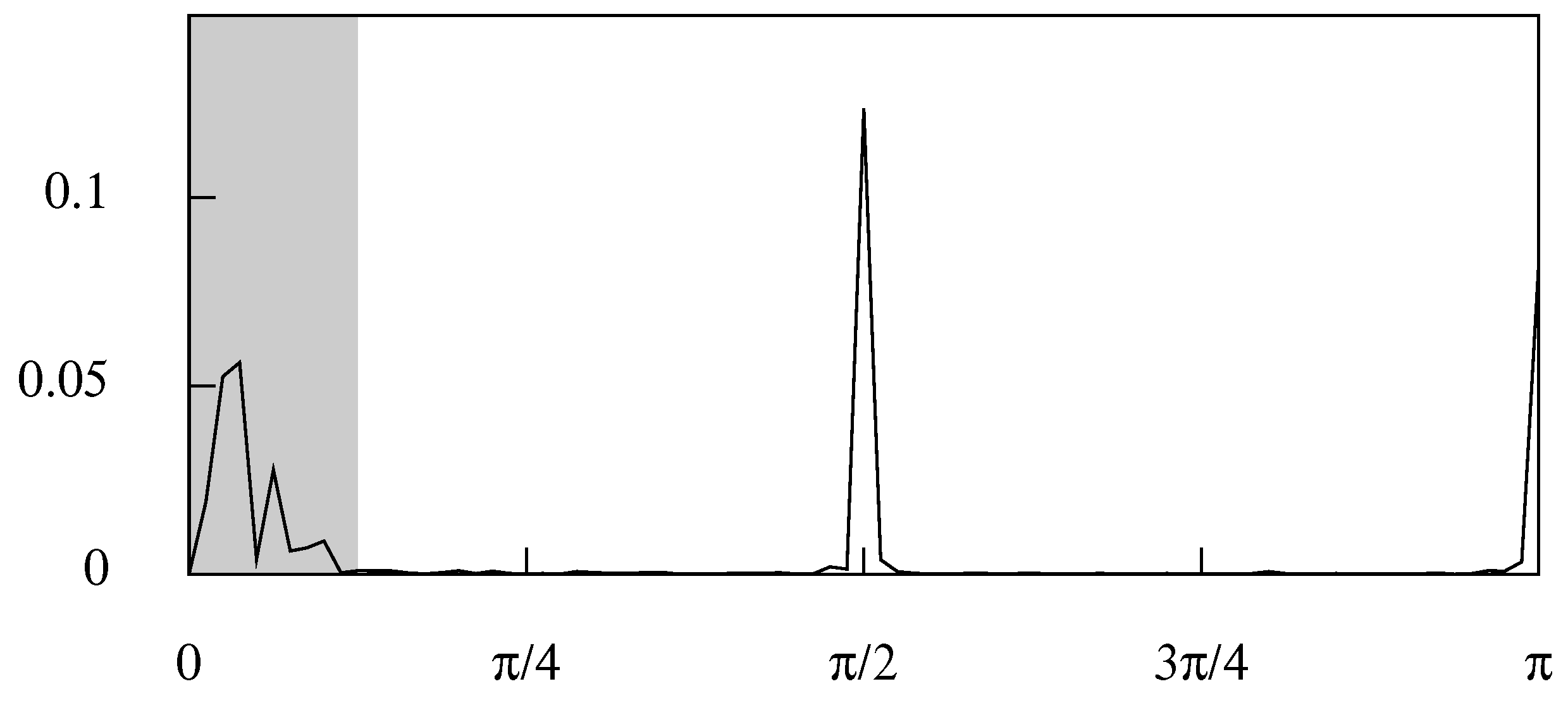
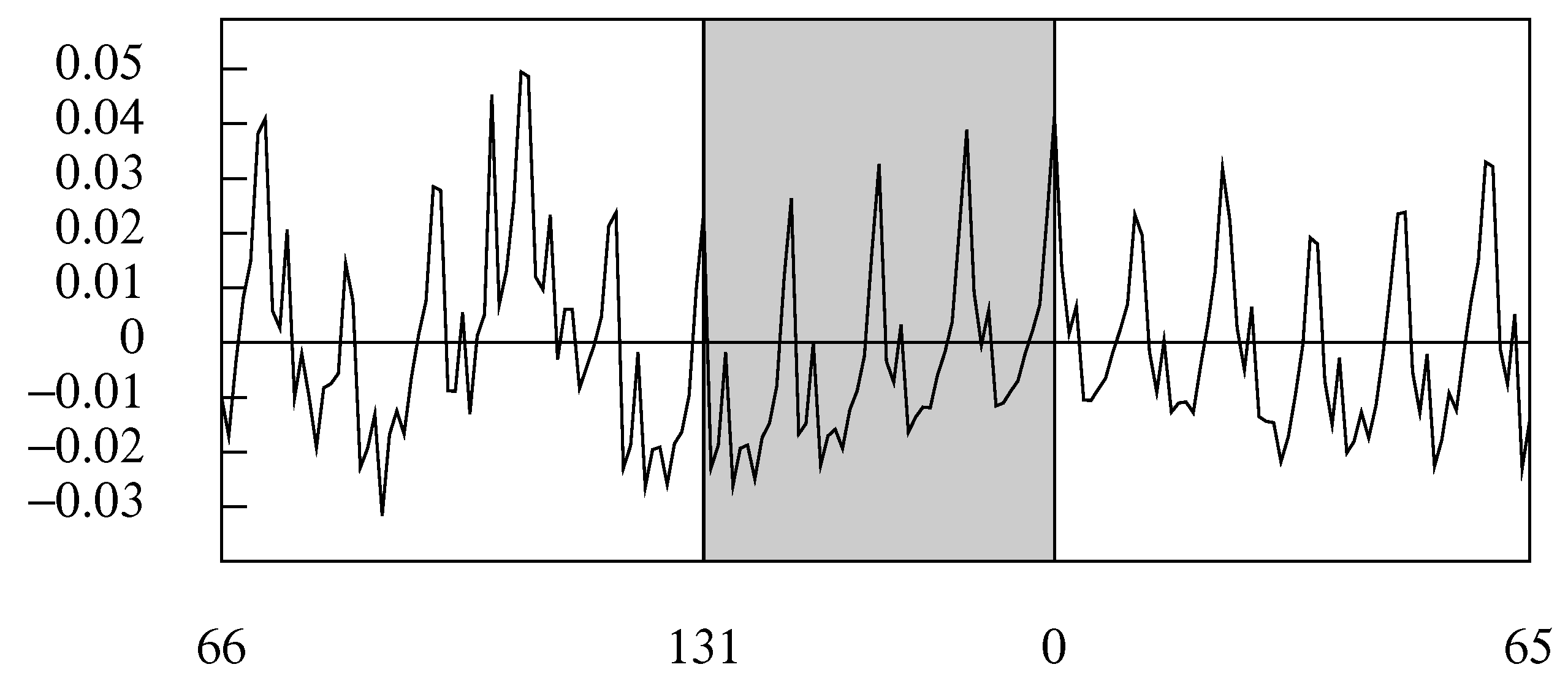
Figure 12 shows the deviations from a linear trend of the logarithms of a quarterly sequence of U.K. domestic expenditure. The data are beset by seasonal fluctuations that have a frequency of radians per sampling interval. However, Figure 13 shows that the business cycle, which accounts for the major fluctuations, has a spectra structure that falls within a shaded band bounded by a maximum frequency of radians per sampling interval.
A smooth trajectory, corresponding to the business cycle, can be synthsised from the Fourier coefficients that fall in the interval . The trajectory, which can be envisaged as a product of an ideal low pass filtering operation, is depicted in Figure 12. The sample on which the ARMA model should be based could be obtained by resampling this trajectory at the rate of one observation in every time units.
However, in this case, it is sufficient to obtain the sample by taking one in every eight of the data points of the filtered sequence. The periodogram of the subsampled data, overlayed by the parametric spectrum of an estimated second-order autoregressive model, is shown in Figure 14. This periodogram is an expanded version of the spectral structure that is highlighted in Figure 13.
5. Graded Filters
An instantaneous event will be represented in a continuous-time data steam by an isolated spike. The spectral signature of such an impulse is spread uniformly over the entire real line. An instantaneous event will also be reflected in a sampled data sequence by a discrete impulse, which has a uniform spectrum over the interval .
The effect of filtering the sequence by an ideal low pass filter will be to remove the high-frequency component of the impulse. This is liable to make the event undetectable in the smoothed sequence, which will lack the necessary temporal resolution.
According to Heisenberg’s uncertainty principle, there is an inverse relationship between the dispersion of a function in the time domain and the dispersion of its Fourier transform in the frequency domain. Therefore, in order to improve the temporal resolution of the smoothed sequence, one should increase the dispersion of the frequency response function of the filter. This can be achieved by allowing a gradual transition from the pass band to the stop band.
5.1. Gaussian Filters
Heisenberg’s uncertainty principle places a bound on the product of the dispersion of a function and that of its Fourier transform. The bound is attained by the Gaussian function and its transform, which is also a Gaussian function. By adopting this function, one can achieve an optimum trade-off of the resolutions of the two domains. (For an excellent brief account of the uncertainty principle, in which there is also a characterisation of the sinc function, see Nahin 2006).
The Gaussian function and its Fourier transform are given by
where , which is the product of the standard deviations.
The function is continuous and, in common with its transform, it is supported on the entire real line. Therefore, in order to create a viable discrete-time filter, it is necessary to sample the function and to truncate the resulting sequence. Since the function decays rapidly, it may be acceptable to form a time-domain filter from a limited number of the sampled coefficients, indexed by , where , with .
A two-dimensional Gaussian filter is commonly used in image processing. The one-dimensional filter can be used in a time-series analysis when it is required to smooth a data sequence of which the spectrum extends over the Nyquist range and when there are no clearly delimited spectral structures that one might wish to isolate.
5.2. The Binomial Filter
An alternative way of creating a graded low pass filter is to employ the approximations to a Gaussian distribution that are provided by the binomial distribution. The coefficients of the low pass filter are
where . The coefficients of the filter can be generated via a simple recursion that connects
When , the ratio of the two is , whence
The z-transform of the sequence of binomial coefficients is . This corresponds to a one-sided filter that looks only backward in time. The z-transform of the symmetric phase-neutral binomial filter is
which is obtained by multiplying that of the backward-looking filter by to shift it forwards in time. The frequency response, which is obtained by setting and by invoking the result (A8) of the appendix, is
In common with other FIR filters, the binomial filter cannot reach the ends of the sample unless the data are supplemented at both ends by m extra-sample points. We continue to assume that the data are free of trends. In that case, the extra points can be provided by reflecting the succeeding and preceding m points around the lower and the upper end points respectively and thereafter, if necessary, by applying a taper that successively reduces the absolute values of these points as their distances from the end points increase (see Section 6.1).
5.3. Wiener–Kolmogorov Filters and the Butterworth Filter
In practice, one might wish to choose the cut-off frequency for the filter and to proceed to determine an appropriate rate of transition about that point. The Butterworth filter is appropriate to this purpose.
The complementary low pass and high pass Butterworth filters, denoted by and , respectively, fulfil the following conditions:
The conditions of phase neutrality of (ii) are by virtue of the symmetry of the filters. The conditions of complementarity and phase neutrality under (i) and (ii) are satisfied by specifying that
where
These two equations define the structure of a Wiener–Kolmogorov digital filter.
The condition under (iii) and (iv) ensure that the low pass filter has unit gain at zero frequency and that the high pass filter has unit gain at the Nyquist frequency of . They can be satisfied by specifying that
where n is a positive integer. Putting these specifications into (45) and (46) gives
and
When within
this becomes the ratio of and , which is . It follows that the frequency response functions of the low pass and high pass filters are
The parameter governs the location of the midpoint of the transition from the pass band to the stop band of the low pass filter and conversely for the high pass filter. It will be observed that, when , there is a perfect symmetry between the two filters, which become the reflections of each other about a vertical line located at the frequency value of . Moreover, at that point, which is the midpoint of both transitions, the value of the gain is .
The midpoint of the transition can be located at any frequency . By solving the equation , it is found that the value of that locates the midpoint at is
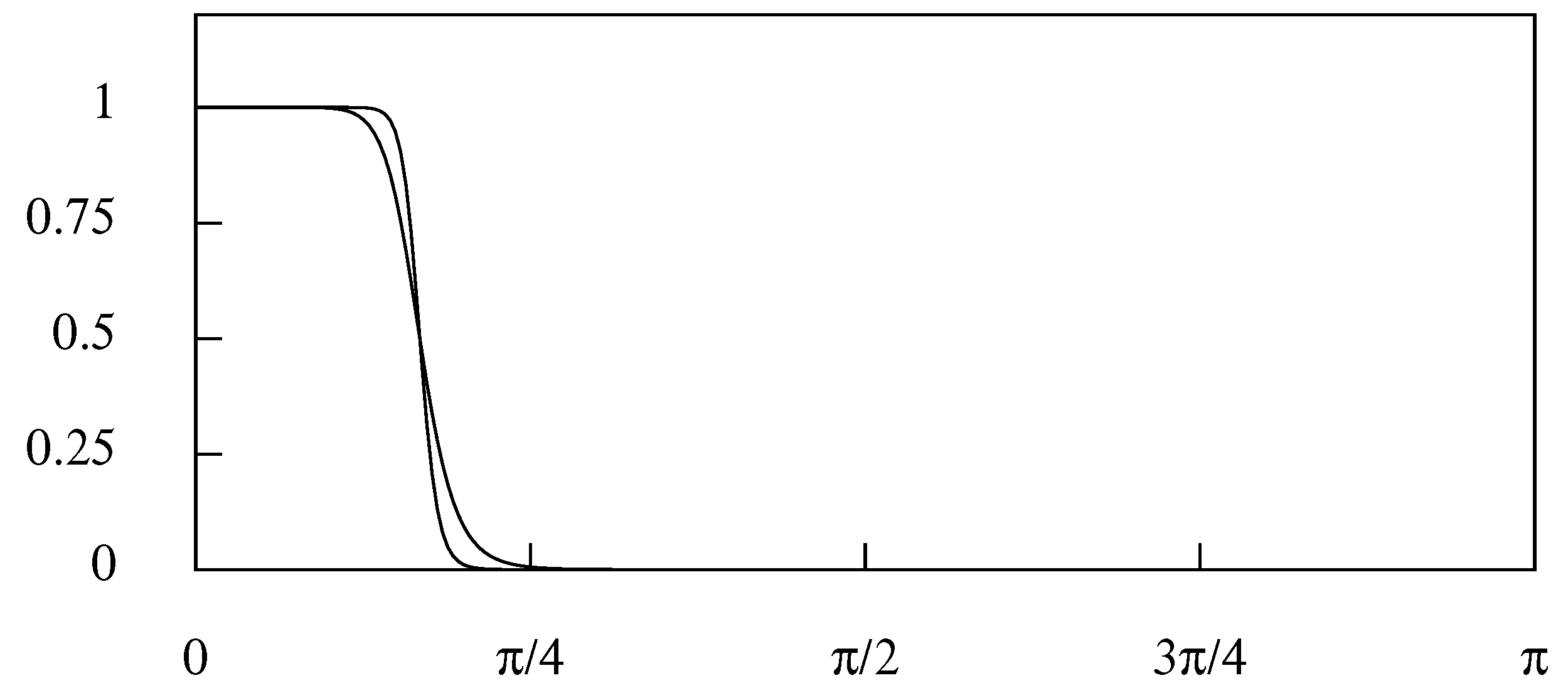
The parameter n, which denotes the order of the filter, is used to govern the rate of transition between the pass band and the stop band. The rate of transition increases as the value of n increases. This is illustrated in Figure 15.
Whereas n must take a positive integer value in the time-domain versions of the filter, it can be a positive real number in the frequency-domain versions, which employ the functions and to rescale the Fourier ordinates of the data.
5.4. The Hodrick–Prescott Filter
A Wiener–Kolmogorov filter that is commonly deployed in econometric analyses is one that has been attributed to Hodrick and Prescott (1980, 1997), which should also be attributed to Leser (1961), who provided an earlier exposition.
In terms of the structures of Equations (45) and (46), the filter is specified by setting
The resulting low pass and high pass versions are
whereas their frequency response functions, which depend on the results of (A5) in Appendix A, are
In common with the Butterworth filter, the Hodrick–Prescott filter must be allied to a method for coping with short trended data sequences, if it is to be fully adapted for econometric circumstances. Two such adaptations are described in the sequel, which are appropriate, respectively, to the frequency-domain and the time-domain implementations of the filters.
The Hodrick–Prescott filter has been used as a low pass smoothing filter in numerous macroeconomic investigations, where it has been customary to set the smoothing parameter to certain conventional values. Thus, for example, the econometric computer package Eviews 4.0 (QMS 2000) imposes the following default values:
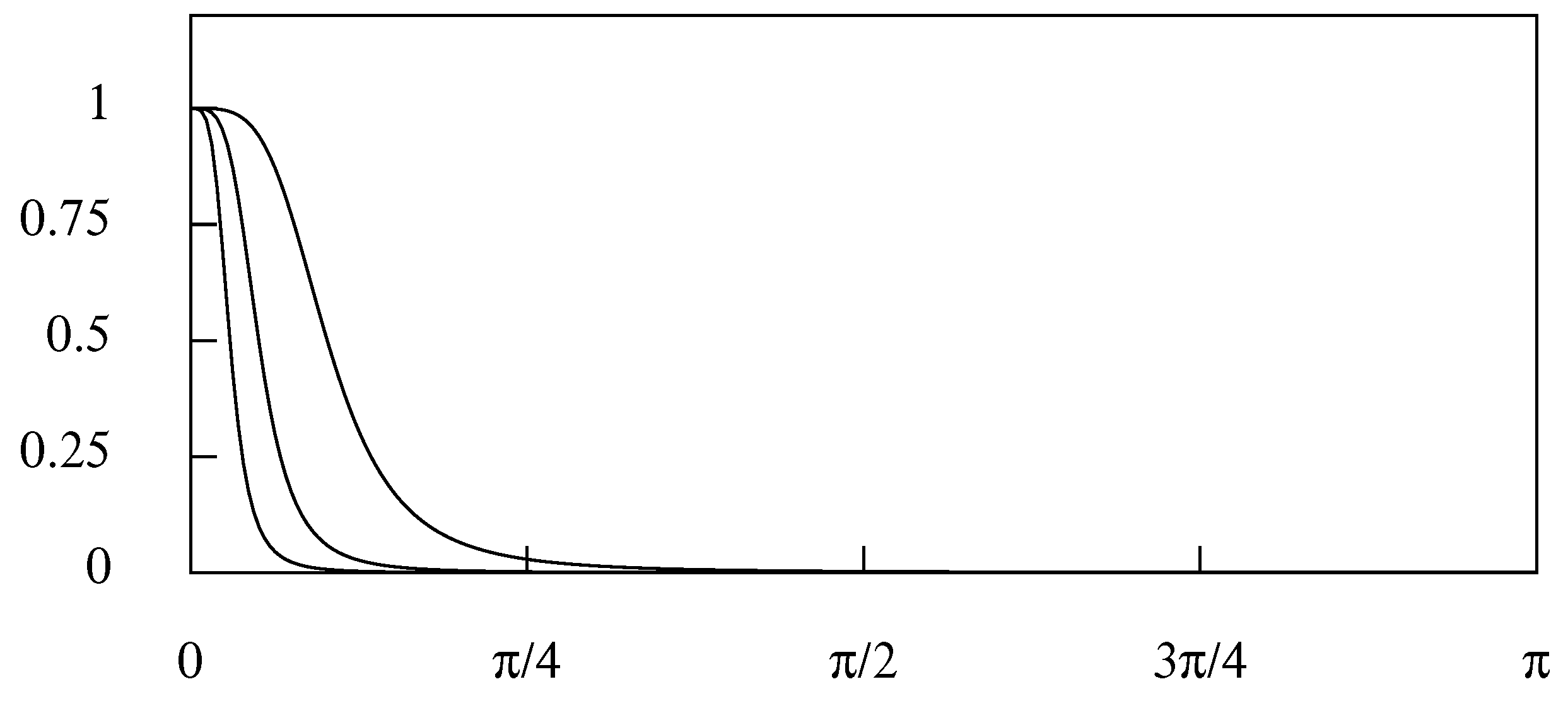
Figure 16 shows the square gain of the filter corresponding to these values. The innermost curve corresponds to and the outermost curve to .
Whereas they have become conventional, these values are arbitrary. The filter should be adapted to the purpose of isolating the component of interest; and the appropriate filter parameters need to be determined in the light of the spectral structure of that component, such as has been revealed in Figure 13, in the case of the U.K. consumption data.
It will be observed that a Hodrick–Prescott filter with , which defines the middle curve in Figure 16, will not be effective in isolating the low-frequency component of the quarterly consumption data of Figure 13, which lies in the interval . The curve will cut through the low-frequency spectral structure that is represented in Figure 13; and the effect will be greatly to attenuate some of the elements of the component that should be preserved intact.
Lowering the value of in order to admit a wider range of frequencies will create a frequency response with a gradual transition from the pass band to the stop band. This will be equally inappropriate to the purpose of isolating a component within a well-defined frequency band; and a different filter is required.
For this purpose, a filter with a rapid transition and a well-placed cut-off frequency is needed. The requirement can be particularly stringent in the case of monthly data affected by seasonal variations. Then, the fundamental seasonal frequency is likely to be close to the upper limit of the business-cycle frequencies; and a sharp cut between the two is called for. In that case, an ideal frequency-domain filter or a Butterworth filter with of a high order may serve the purpose.
6. Adapting the Filters to Short and Trended Data
The typical econometric data sequence is of a limited duration, and it may also show a marked trend. The theory of filtering typically presupposes that the data are generated by a statistically homogeneous process of infinite duration that shows no trends. Some significant adaptations are required in order to accommodate the econometric realities.
6.1. Extrapolations of the Data
The methods for adapting the Henderson FIR filters to trended data have been discussed in Section 3. In the case of data that are deemed to have been generated by a statistically stationary mean-zero process, it may be appropriate to proxy the extra-sample elements by their zero-valued unconditional expectations.
In the case of a process embodying a first-order random walk—attributable to a single unit root within an autoregressive operator—it may be appropriate to extrapolate the data at the levels of the end points. This is the basis of a method proposed by Christiano and Fitzgerald (2003).
A more careful procedure that can be followed in the case of trend-free data is to reflect the data around the endpoints to create m extra-sample points at each end, sufficient to enable the filter to generate values and to replace the data values and . A taper can also be applied to these extrapolations whereby they should converge towards zero. This is a procedure to follow whenever the values at the end points are significantly different from their zero expectations.
An alternative and an equivalent recourse is to fold back the filter coefficients that would otherwise extend beyond the ends of the sample and to add them to the coefficients that lie within the sample. Thus, for example, in the case of , the following filters would be applied at the upper end of the sample:
Here, is the factor that imposes a taper on the folded coefficients.
The first of these expressions represents the ordinary symmetric filter that looks equally back and forwards in time, whereas the last of them, which represents the final filter, looks only back in time. At the lower end, a similar set of filters would be applied, but with z interchanged with .
The end-of-sample problem is liable to affect filters that are applied in the frequency domain to no lesser extent than those that are applied in the time domain. This is notwithstanding the fact that the implicit circularity of the data allows filtered values to be generated at both ends of the sample.
In creating the circular data sequence, the head of the sample is joined to its tail, and the extra-sample points at the beginning of the sample are proxied by values from the end of the sample, and vice versa. However, there may a significant difference between the values at the head and the tail, leading to a radical disjunction in the circular data at the point where they are joined.
This circumstance justifies the addition of tapered extrapolations to both ends of the sample. To avoid a disjunction in the circular sequence, the two extrapolations should reach the same value at their furthest points. This can be a achieved using the weights
which descend from unity when , which marks an endpoint of the sample, to zero when , which marks the terminal point of the extension.
In the case of data that have an evolving pattern of seasonal variation, Pollock (2016) has proposed to interpolate into the circular data sequence, at the point of the juncture, a synthetic data sequence in which the seasonal pattern of the final years is gradually transformed into the pattern of the initial years. The transformation is by virtue of a weighted average of the two patterns, wherein the evolving weights are governed by a logistic curve based on the half-cycle of a cosine function. An example is provide by Figure 17.
6.2. The Interpolation of a Trend Function
There are two common methods of removing the trend from the data that seem to be very different. The first method relies on the interpolation of a trend function, which is commonly a polynomial function, by a method of least-squares regression. The end-of-sample problem can be alleviated by attributing extra weight to the data at the ends of the sample in order to bring them and the regression line closer together. Then, there can be more justification for using zeros as proxies for the extra-sample elements.
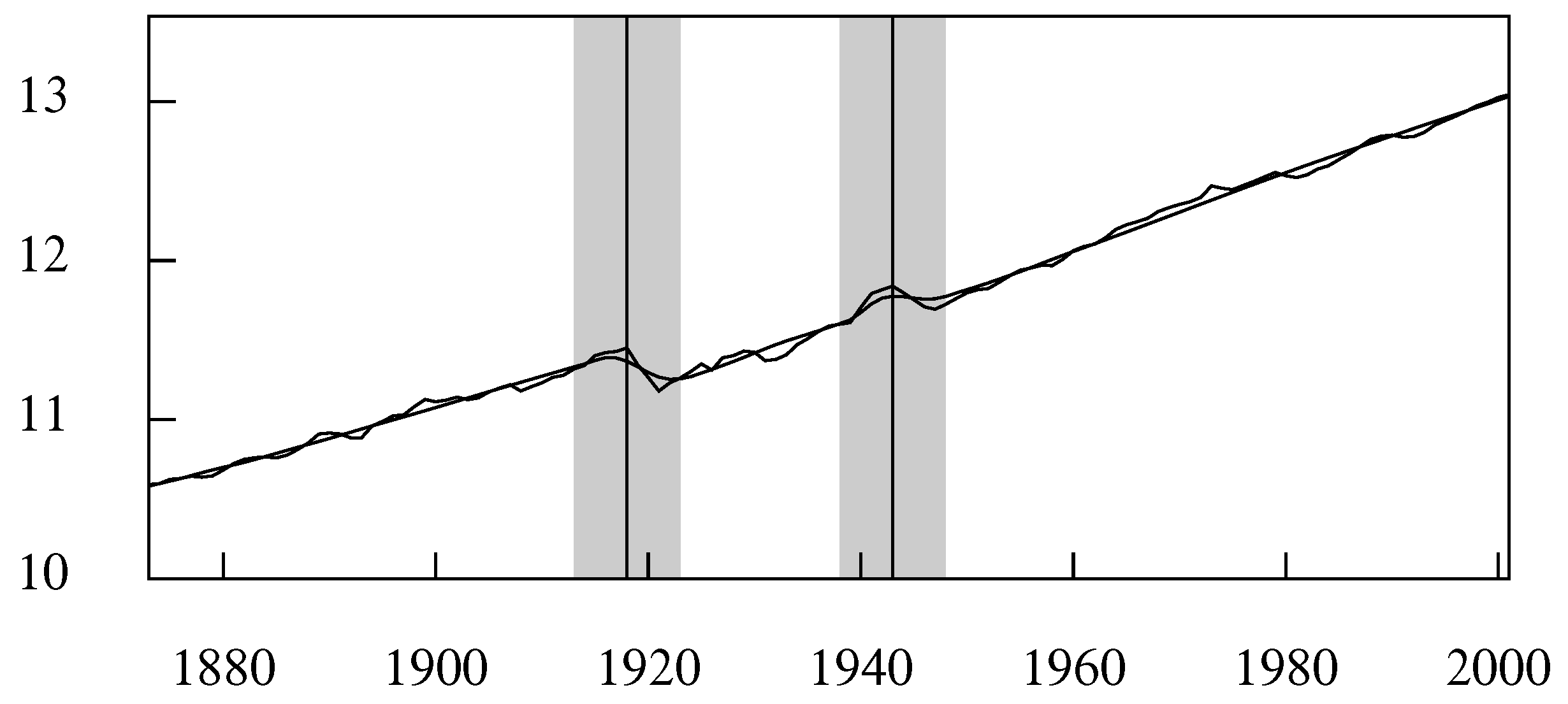
A trend can also be interpolated into the data by the Hodrick–Prescott filter, with a high degree of smoothing. A version of Hodrick–Prescott filter with a smoothing parameter that is allowed to vary over the length of the data has also been provided by Pollock (2016). By setting the smoothing parameter to a low value in the vicinity, a so-called structural break in the data can be absorbed by the trend, which maintains its stiffness in other regions (see Figure 18).
Once the data have been subjected to a preliminary detrending, the residual sequence can be subjected to the filtering procedures that are applicable to non-trended data. If this is a low pass filtering, designed to isolate the low-frequency cycles of the data, then the filtered sequence can be added to the estimated trend to create a trend-cycle trajectory.
6.3. The Differencing and Anti-Differencing in the Time Domain
Another common way of removing the trend from the data sequence is to apply a differencing operator. Usually, a twofold differencing operator is appropriate, which will serve to reduce a linear trend to zero. In the case of backward differences, the twofold operator takes the form of
The matrix form of the operator, which is applicable to a finite data vector , is illustrated, in the case of , by
The first two rows, which do not produce true differences, are liable to be discarded.
The twice differenced sequence can be filtered and then it can be re-inflated or anti-differenced with the help of the twofold summation operator, which is
The matrix version of the operator for is
The twofold summation operator must be accompanied by two initial conditions to compensate for the loss of two data points in forming the vector of second differences. If a low pass filter with a unit gain at zero frequency has been applied, then the initial conditions should be determined such as to bring the re-inflated sequence into as close an alignment as possible with the data. The same criterion is applied in finding the initial conditions for the re-inflation of the complementary high pass component.
Let x and h be, respectively, the low pass and the high pass component of the data vector . These must be recovered from their differenced versions and , which are the components of the vector that is subject to the filtering. The recovered vectors are
and
Here, and are the initial conditions that are obtained via the minimisation of the function
which ensures that the estimated trend x adheres as closely as possible to the data y.
In the case where the data are differenced twice, there is
The elements of the matrix can be found via the formulae
A compendium of such results has been provided by Jolly (1961), and proofs of the present results were given by Hall and Knight (1899).
6.4. Centralised Differences
The elimination of the trend can also be accomplished by a centralised operator of the form
The frequency-response function of the operator, which is obtained by setting in this equation, and by invoking the result (A5) of Appendix A, is
This is zero at zero frequency. The frequency response of the anti-differencing operator has an indefinite value at zero frequency,
The matrix version of the centralised operator can be illustrated by the case where :
In applying this operator to the data, the first and the last elements of , which are and , respectively, are not true differences. Therefore, they are discarded to leave . To compensate for this loss, appropriate values are attributed to and , which are formed from combinations of the adjacent values, to create a vector of order T denoted by .
6.5. The Binomial Filter with Trended Data
The centralised difference operator can be used in conjunction with the binomial filter. The operator is used to eliminate a trend in the data, whereafter the complementary high pass filter is applied to the differenced data.
The z-transform of the high pass filter is
This can be compounded with the anti-differencing operator , which is the inverse of the difference operator, to create a reduced filter
Whereas has zeros at the Nyquist frequency of the complementary high pass filter has zeros at zero frequency. These will serve to nullify the unbounded inflationary effect of at zero.
The frequency response function of the compound filter is
When the filter is applied to the differenced data, it will create a high pass component, which can be subtracted from the data to create the low pass component.
Apart from the initial application of the centralised difference operator, which will be in the time domain, the essential processing can take place in either domain. In the frequency-domain implementation, a Fourier transform must be applied to the diffenced data, whereafter the weighting function of (73) will be applied to the Fourier ordinates. Then, the results will be translated back to the time domain by an inverse Fourier transform.
6.6. The Wiener–Kolmogorov Frequency-Domain Filters with Trended Data
The phase-neutral frequency response of the anti-differencing operator can be applied in the frequency domain in conjunction with a high pass filter that operates in that domain, provided that the filter has multiple zeros at zero frequency.
An example is provided by the Butterworth filter. The product of the frequency response of the high pass filter with that of the anti-differencing operator is
This function can be used to rescale the ordinates of the Fourier transform of the differenced data. The product can then be subjected to an inverse Fourier transform to carry it into the time domain, and the result can be subtracted from the data to create the low pass component.
A similar procedure can be followed in the case of the Hodrick–Prescott filter, for which the product of the frequency response of the high pass filter with that of the anti-differencing operator is
7. The Finite-Sample Time-Domain Wiener–Kolmogorov Filters
An alternative to applying the Wiener–Kolmogorov filter in the frequency domain is to adopt a procedure that remains strictly within the time domain. Such an approach has been expounded in detail by Pollock (2007). The minimum mean-square-error filters can be derived, variously, according a least-squares criterion, a maximum-likelihood criterion and a conditional expectations criterion, which are equivalent.
The filters that are appropriate to statistically stationary data are recognisable variants of the filters depicted in Equations (48) and (49), in which the difference and summation operators are replaced by matrix analogues. The filters for trended data that can be reduced to stationarity by twofold differencing are more complicated.
The low pass component of the trended data that is isolated by the Hodrick–Prescott filter is
where is the smoothing parameter. The filter is formed by subtracting the high pass filter from the identity matrix.
As , the vector x tends to that of a linear function interpolated into the data by least-squares regression, which is represented by the equation .
The Butterworth filter that is appropriate to short trended sequences produces the following low pass component:
Here, the matrices
are obtained from the RHS of the equations and , respectively, by replacing z by and by , where is the matrix lag operator of order T, which is obtained from the identity matrix by deleting the first column and by appending a column of zeros at the end.
Observe that the equalities no longer hold after the replacements. However, it can be verified that
One may also observe that the high pass Wiener–Kolmogorov filters for trended data give the same results whether they are applied to the original data or to the residuals from a linear detrending that are contained in the vector . This follows since .
It is also clear that the residual vector contains the same information as the vector of the second differences. Thus, linear detrending and differencing, which appear to be very different ways of removing a trend, can lead to the same results.
The virtue of the finite-sample Wiener–Kolmogorov filters is that they avoid the end-of-sample problem by remaining within the sample and by adapting the filter coefficients continuously according to their location.
Figure 19 shows a sequence of filter coefficients from a finite-sample low pass Butterworth filter of order and with a cut off point at radians or . The size of the sample is and the filtered value is dated by .
It can be seen from Equation (77) that the filter matrix is not symmetric. Therefore, the filter coefficients of the tth row will differ from the coefficients in the tth column, which correspond to the response to an impulse at time t. The differences are only significant in small samples.
8. Conclusions
The filters that are commonly deployed in econometric analyses operate exclusively in the time-domain. They often require complicated data extrapolations to cope with the end-of-sample problems that arise when the data are trended. There is much doubt and dispute over the criteria that should inform the design of time-domain econometric filters.
In this paper, it has been proposed that the filters should be designed with reference to their frequency responses. In that case, it is natural that they should also be implemented in the frequency domain. To do so requires that the data should be free of trends. This can be achieved in a variety of ways that have been described in the paper. Working with trend-free data alleviates the end-of-sample problem. Alternative means of restoring the trends after the trend-free data have been processed have also been described.
The methods and procedures that have been discussed in the paper have been implemented in a program called IDEOLOG, which is available, together with its code in Pascal, at the address http://www.le.ac.uk/users/dsgp1/. The program facilitates the comparison of different filters. It includes some filters of which the use has been derogated by the author. (For a critique of some of these filters, see Pollock 2014 and Pollock 2016).
Several of the filters have been implemented in the program both in the time domain and in the frequency domain. Given the equivalence of the results, the user should be indifferent regarding the choice of which version to use. However, it can be argued that, from the point of view of a theory of filtering and for ease of implementation, the frequency-domain versions are to be preferred.
Funding
This research received no external funding.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Fourier Transforms—Sampling and Wrapping
Appendix A.1. Euler’s Equations
In describing the Fourier transforms, it is easiest to express the results in terms of complex exponential functions whereas, in practice, they are computed with trigonometric functions. Euler’s equations express the trigonometric functions as follows:
Conversely, there are
Euler’s equations can be used in finding the frequency responses of certain operators that are expressed in terms of their z-transforms.
Consider the centralised twofold difference operator, which is
On setting , this becomes . Consider also
Setting gives whence
The apex operator, which is an element of the binomial filter and which is also present in the Butterworth filter, is
On setting , we get . There is also
Setting gives whence
Appendix A.2. The Variety of Fourier Transforms
The various Fourier transforms that have been deployed in this paper can be derived by applying successive sampling processes to the Fourier Integral Transform, which is defined as follows:
The sequence is derived by sampling at unit intervals in the time domain. The frequencies within the sequence are limited to radians per sampling interval, and the relevant transformation is now the so-called Discrete-time Fourier Transform:
Given that , the LHS of (A10) must equate at the integer points with the LHS of (A9). For this, it is necessary that
which is a periodic function supported on the Nyquist interval . This function is obtained by wrapping around a circle of circumference and adding the overlying ordinates.
Next, the function may be sampled at T points in the interval , which are , to create the sequence . This is joined to a sequence of T points in the time domain via the Discrete Fourier Transform:
Given that , the RHS of (A12) must equate with the RHS of (A10) at that point. For this, it is necessary that
Thus, the sequence is obtained by wrapping the sequence round a circle of circumference T and adding the overlying ordinates.
It is also possible to proceed from Equation (A9) by sampling in the frequency domain at intervals of radians, where T is the time that it takes a function of frequency to complete a single cycle. The resulting sequence is ; and the relevant transform is known as the Classical Fourier Series:
Here, we may write , where , as before. Comparison with Equation (A9) shows that, in order to maintain the equality , it is necessary that
which defines a continuous periodic function supported on the interval .
One may proceed from here to to Discrete Fourier Transform of (A12) by sampling the periodic function at unit intervals within . Then, comparison of (A12) and (A14) shows that, in order to maintain the equality at the integer points, it is necessary that
Observe that and are obtained by wrapping and sampling the functions and respectively, and that these two operations commute.
Appendix A.3. The Wrapped Coefficients of the Ideal Lowpass Filter
Let the sample size be T, and consider a set of T frequency-domain ordinates sampled, from a boxcar function centred on , at the Fourier frequencies that fall within the interval . If the cut-off points are at , then the ordinates of the sample will be
Their (discrete) Fourier transform, scaled by , is the sequence of the coefficients
defined for .
The ordinates cause some inconvenience in evaluating this transform. This can be overcome by evaluating the function
where , together with the function . Then, the symmetric function can be formed, wherafter setting produces the kth filter coefficient.
First, consider
Multiplying top and bottom by gives
Then, setting gives
When , this becomes
which is the Dirichlet function multiplied by a complex exponential that owes its presence to the non-symmetric nature of . There is also
Therefore, for , there is
whereas, for , there is , which comes from setting in the expression for of (A.19) and in the analogous expression for .
In an alternative specification of the ideal filter, the cut-off points fall between Fourier frequencies. Then, the ordinates sampled from the frequency response function are
In place of , there is
Then, for , there is , whereas, for , the formula is
References
- Abramovich, Felix, Trevor C. Bailey, and Theofanis Sapatinas. 2000. Wavelet Analysis and its Statistical Applications. Journal of the Royal Statistical Society: Series D (The Statistician) 49: 1–29. [Google Scholar] [CrossRef] [Green Version]
- Baxter, Marianne, and Robert G. King. 1999. Measuring Business Cycles: Approximate Band-Pass Filters for Economic Time Series. Review of Economics and Statistics 81: 575–93. [Google Scholar] [CrossRef]
- Burns, Arthur F., and Wesley C. Mitchell. 1946. Measuring Business Cycles. New York: National Bureau of Economic Research. [Google Scholar]
- Christiano, Lawrence J., and Terry J. Fitzgerald. 2003. The Band-pass Filter. International Economic Review 44: 435–65. [Google Scholar] [CrossRef]
- Cooley, James W., and John W. Tukey. 1965. An Algorithm for the Machine Calculation of Complex Fourier Series. Mathematics of Computation 19: 297–301. [Google Scholar] [CrossRef]
- Doherty, Mike. 2001. The Surrogate Henderson Filters in X-11. Australian and New Zealand Journal of Statistics 43: 385–92. [Google Scholar] [CrossRef]
- Fishman, George S. 1969. Spectral Methods in Econometrics. Cambridge: Harvard University Press. [Google Scholar]
- Granger, Clive William John, and Michio Hatanaka. 1964. Spectral Analysis of Economic Time Series. Princeton: Princeton University Press. [Google Scholar]
- Gray, Alistair G., and Peter J. Thomson. 2002. On a Family of Finite Moving-average Trend Filters for the Ends of Series. Journal of Forecasting 21: 125–49. [Google Scholar] [CrossRef]
- Guerlac, Henry. 1947. Radar in World War II. Volume 1 of MIT Radiation Laboratory Series; New York: McGraw-Hill. [Google Scholar]
- Hall, Henry Sinclair, and Samuel Ratcliffe Knight. 1899. Higher Algebra. London: Macmillan and Co. [Google Scholar]
- Henderson, Robert. 1916. Note on Graduation by Adjusted Average. Transactions of the Actuarial Society of America 17: 43–48. [Google Scholar]
- Henderson, Robert. 1924. A New Method of Graduation. Transactions of the Actuarial Society of America 25: 29–40. [Google Scholar]
- Hodrick, Robert J., and Edward C. Prescott. 1980. Postwar U.S. Business Cycles: An Empirical Investigation, Working Paper. Pittsburgh: Carnegie Mellon University.
- Hodrick, Robert J., and Edward C. Prescott. 1997. Postwar U.S. Business Cycles: An Empirical Investigation. Journal of Money, Credit and Banking 29: 1–16. [Google Scholar] [CrossRef]
- Henney, Keith, ed. 1953. Index, Volume 28 of MIT Radiation Laboratory Series. New York: McGraw-Hill. [Google Scholar]
- Jolly, Leonard Benjamin William. 1961. Summation of Series: Second Revised Edition. New York: Dover Publications. [Google Scholar]
- Kailath, Thomas. 1974. A View of Three Decades of Filtering Theory. IEEE Transactions on Information Theory 20: 146–81. [Google Scholar] [CrossRef]
- Kenny, Peter B., and James Durbin. 1982. Local Trend Estimation and Seasonal Adjustment of Economic and Social Time Series. Journal of the Royal Statistical Society Series A 145: 1–41. [Google Scholar] [CrossRef]
- Kolmogorov, Andrei Nikolaevitch. 1941. Stationary Sequences in a Hilbert Space. Bulletin of the Moscow State University 2: 1–40. (In Russian). [Google Scholar]
- Kolmogorov, Andrei Nikolaevitch. 1941. Interpolation and Extrapolation. Bulletin de l’Academie des Sciences de U.S.S.R Series Mathematical 5: 3–14. [Google Scholar]
- Kovačević, Jelena, Vivek K. Goyal, and Martin Vetterli. 2013. Fourier and Wavelet Signal Processing. Available online: www.fourierandwavelets.org (accessed on 23 July 2018).
- Ladiray, Dominique, and Benoit Quenneville. 2001. Seasonal Adjustment with the X-11 Method. Springer Lecture Notes in Statistics 158. Berlin: Springer Verlag. [Google Scholar]
- Laniel, Normand. 1986. Design Criteria for 13-Term Henderson End-Weights. Technical Report Working paper TSRA-86-011. Ottawa: Statistics Canada. [Google Scholar]
- Leser, C. E. V. 1961. A Simple Method of Trend Construction. Journal of the Royal Statistical Society, Series B 23: 91–107. [Google Scholar]
- Mallat, Stéphane. 1998. A Wavelet Tour of Signal Processing. San Diego: Academic Press. [Google Scholar]
- Musgrave, J. C. 1964a. A Set of End Weights to End all End Weights, Unpublished Working Paper of the U.S. Bureau of Commerce.
- Musgrave, J. C. 1964b. Alternative Sets of Weights Proposed for X-11 Seasonal Factor Curve Moving Averages, Unpublished Working Paper of the U.S. Bureau of Commerce.
- Nahin, Paul J. 2006. Dr. Euler’s Fabulous Formula. Princeton: Princeton University Press. [Google Scholar]
- Nyquist, Harry. 1928. Certain Topics in Telegraph Transmission Theory. AIEE Transactions, Series B 47: 617–44. [Google Scholar] [CrossRef]
- Oppenheim, Alan V., and Ronald W. Schafer. 1975. Digital Signal Processing. Englewood: Prentice-Hall. [Google Scholar]
- Pollock, D. Stephen G. 2007. Wiener–Kolmogorov Filtering, Frequency-Selective Filtering and Polynomial Regression. Econometric Theory 23: 71–88. [Google Scholar] [CrossRef]
- Pollock, D. Stephen G. 2008. Realisations of Finite-Sample Frequency Selective Filters. Journal of Statistical Planning and Inference 139: 1541–58. [Google Scholar] [CrossRef]
- Pollock, D. Stephen G. 2009. Statistical Signal Extraction and Filtering: A Partial Survey. In Handbook of Computational Econometrics. Edited by David Belsley and Erricos Kontoghiorges. Chichester: John Wiley and Sons, chp. 9. pp. 321–76. [Google Scholar]
- Pollock, D. Stephen G. 2014. Cycles, Syllogisms and Semantics: Examining the Idea of Spurious Cycles. Journal of Times Series Econometrics 6: 81–102. [Google Scholar] [CrossRef]
- Pollock, D. Stephen G. 2016. Econometric Filters. Computational Economics 48: 669–91. [Google Scholar] [CrossRef]
- Rabiner, Lawrence R., and Bernard Gold. 1975. Theory and Application of Digital Signal Processing. Englewood: Prentice-Hall. [Google Scholar]
- QMS. 2000. Eviews 4.0. Irvine: Quantitative Micro Software (QMS). [Google Scholar]
- Ridenour, Louis Nicot. 1947. Radar System Engineering, Volume 1 of MIT Radiation Laboratory Series. New York: McGraw-Hill. [Google Scholar]
- Shannon, Claude Elwood. 1949a. Communication in the Presence of Noise. Proceedings of the Institute of Radio Engineers 37, 10–21. Reprinted in 1998. Proceedings of the IEEE 86: 447–57. [Google Scholar] [CrossRef]
- Shannon, Claude E. 1949b. The Mathematical Theory of Communication. Urbana: University of Illinois Press, Reprinted in 1998. [Google Scholar]
- Shiskin, Julius, Allan H. Young, and John C. Musgrave. 1967. The X-11 Variant of the Census Method II Seasonal Adjustment Program; Technical Paper 15. Washington, D.C.: Bureau of the Census, U.S. Department of Commerce.
- Vetterli, Martin, Jelena Kovacčević, and Vivek K. Goyal. 2014. Foundations of Signal Processing. Available online: www.fourierandwavelets.org (accessed on 23 July 2018).
- Wallis, Kenneth F. 1981. Models for X-11 and X-11-Forecast Procedures for Preliminary and Revised Seasonal Adjustments. Paper presented at the A.S.A–Census–NBER Conference on Applied Time Series Analysis of Economic Data, Washington, D.C., US; pp. 3–11. [Google Scholar]
- Wiener, Norbert. (1941) 1949. Extrapolation, Interpolation and Smoothing of Stationary Time Series. Report on the Services Research Project DIC-6037. Published in book form. Cambridge: MIT Technology Press, New York: John Wiley and Sons. [Google Scholar]
Figure 1.
A diagram to illustrate the effects of aliasing in the process of sampling when there are frequencies beyond the Nyquist range , which defines the innermost circle. Frequencies on the outer circles are mapped onto the inner circle by following the radial lines, e.g. and (The arcs with broken lines correspond to negative frequencies).
Figure 1.
A diagram to illustrate the effects of aliasing in the process of sampling when there are frequencies beyond the Nyquist range , which defines the innermost circle. Frequencies on the outer circles are mapped onto the inner circle by following the radial lines, e.g. and (The arcs with broken lines correspond to negative frequencies).

Figure 2.
The scaling function . The function continues indefinitely in both directions.

Figure 3.
The scaling function . The function continues indefinitely in both directions.

Figure 4.
The wavelet function .

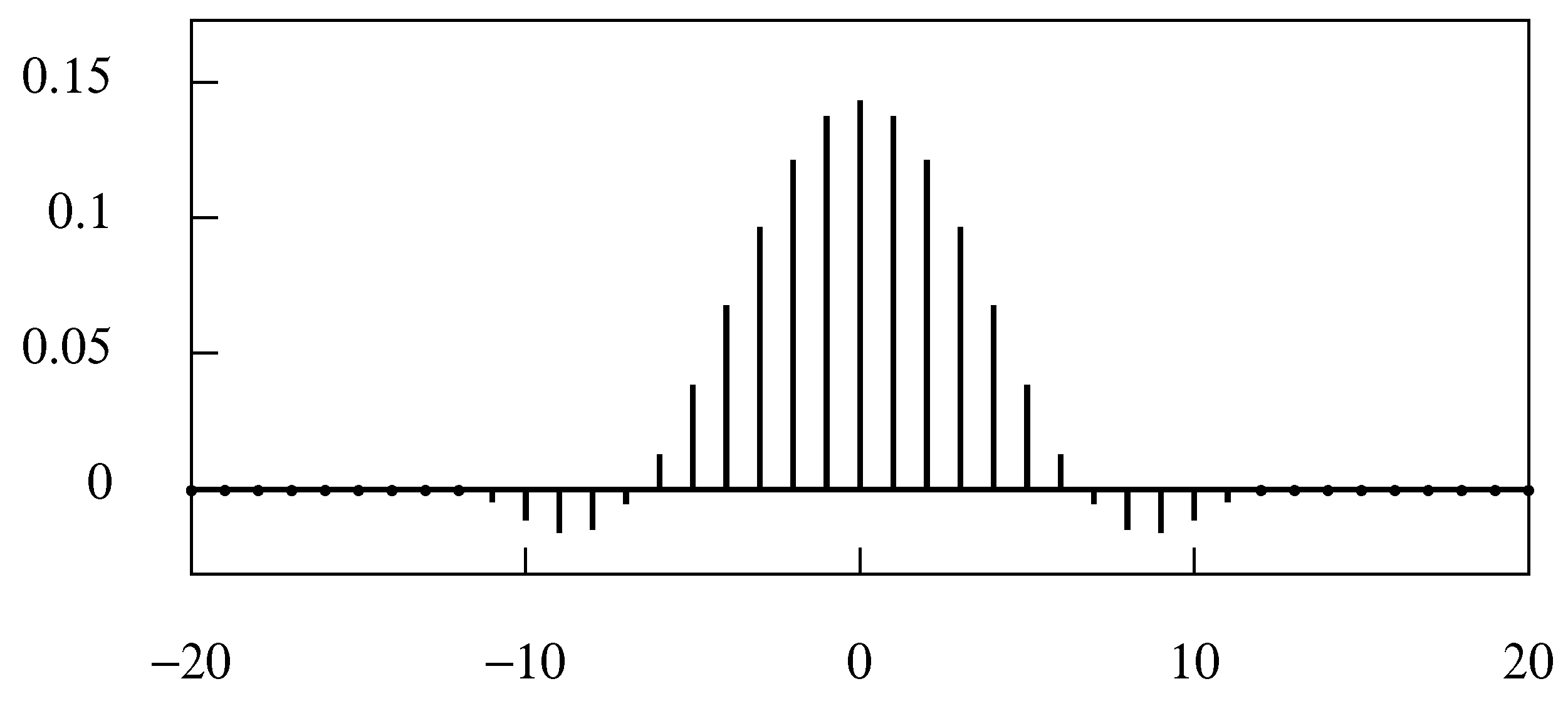
Figure 5.
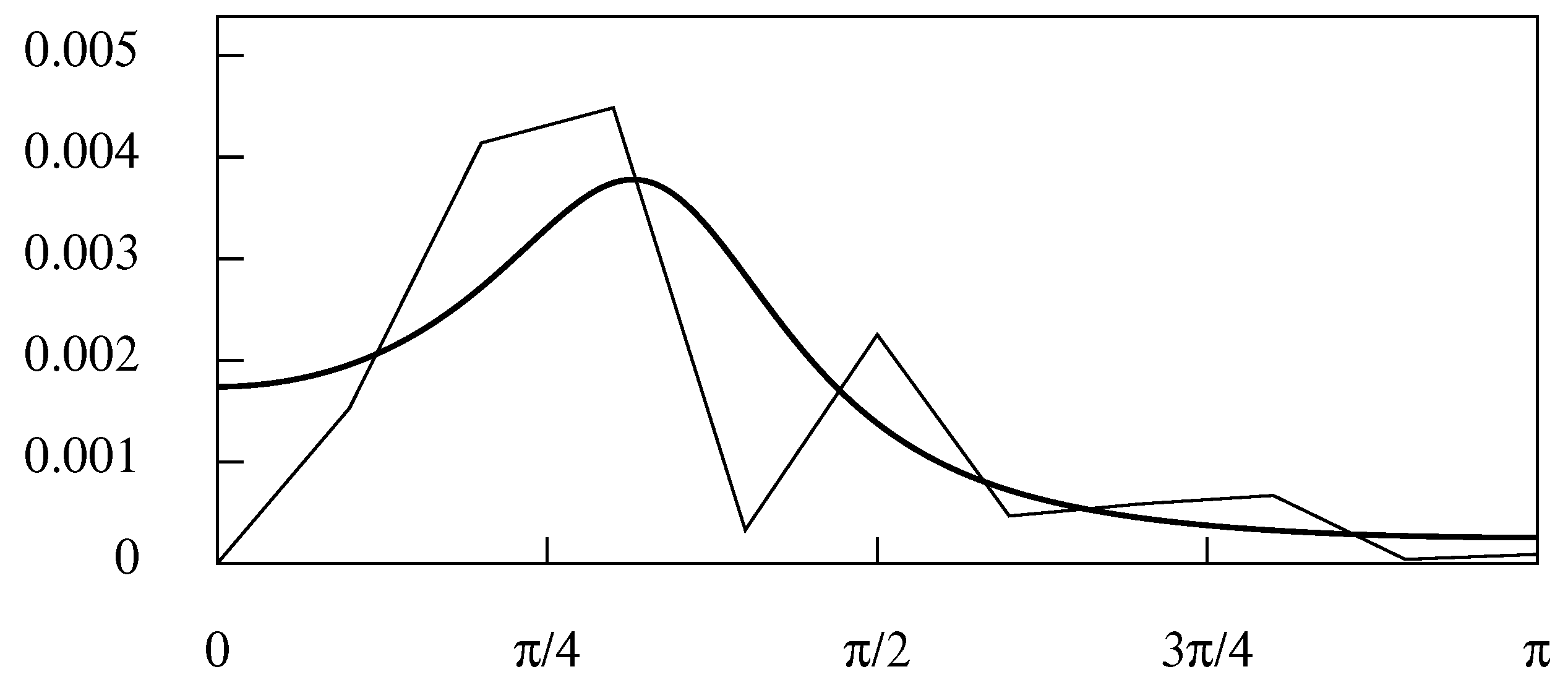
The coefficients of the symmetric Henderson filter of 23 points.

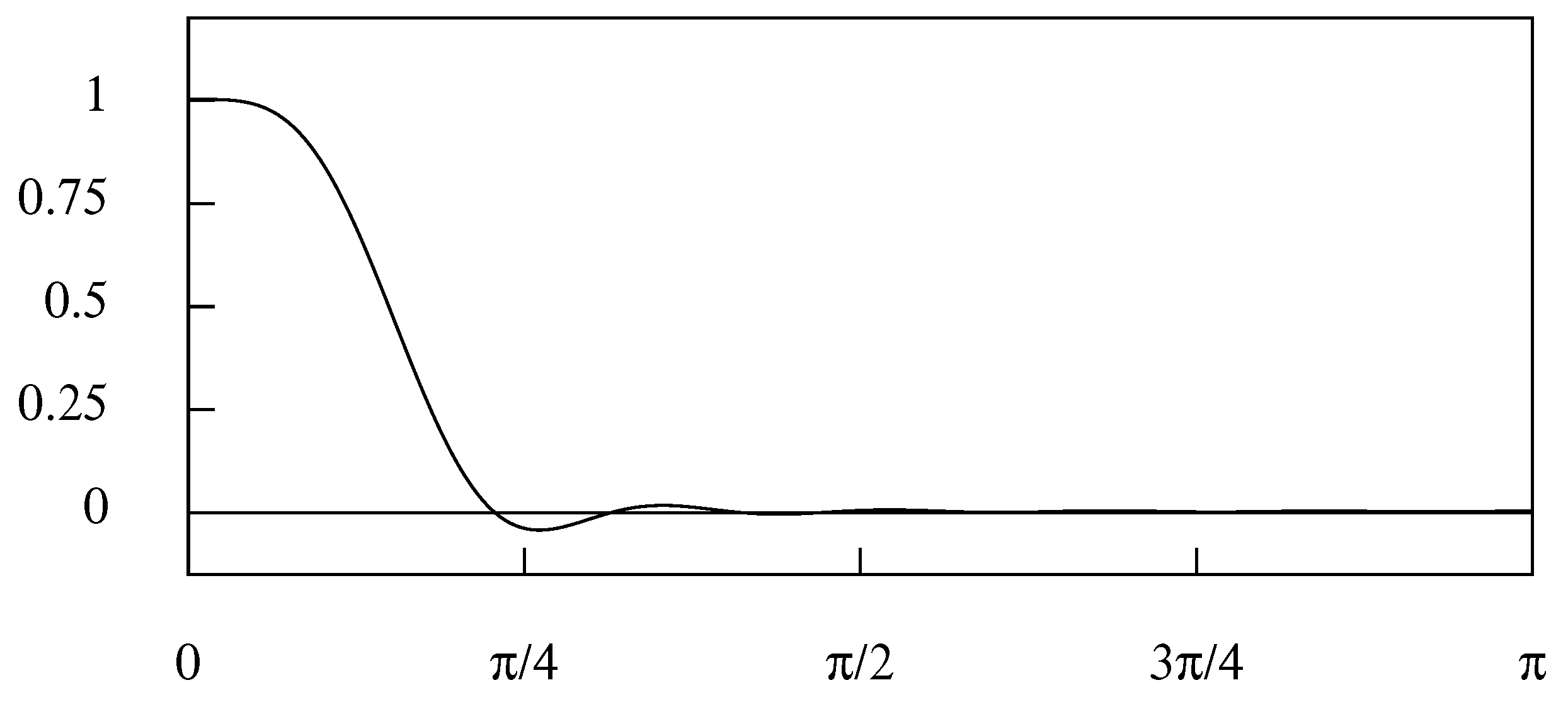
Figure 6.
The frequency response function of the Henderson moving-average filter of 23 terms.

Figure 7.
A trend, determined by a Henderson filter with 23 coefficients, interpolated through 160 logarithms of the quarterly household expenditure in the U.K. for the years 1955 to 1994.
Figure 7.
A trend, determined by a Henderson filter with 23 coefficients, interpolated through 160 logarithms of the quarterly household expenditure in the U.K. for the years 1955 to 1994.

Figure 8.
Two representations of the conversion of a low pass filter to a band pass filter by a cosine modulation, which creates two displaced copies of the low pass filter.
Figure 8.
Two representations of the conversion of a low pass filter to a band pass filter by a cosine modulation, which creates two displaced copies of the low pass filter.

Figure 9.
The rectangular frequency response of the ideal band pass filter defined on the interval , together with the frequency response of the truncated filter of 25 coefficients.
Figure 9.
The rectangular frequency response of the ideal band pass filter defined on the interval , together with the frequency response of the truncated filter of 25 coefficients.

Figure 10.
The frequency response of the 16-point wrapped filter defined over the interval . The values at the Fourier frequencies are marked by circles and dots. Note that, when the horizontal axis is wrapped around the circumference of the unit circle, the points at and coincide. Therefore, only one of them is included in the interval.
Figure 10.
The frequency response of the 16-point wrapped filter defined over the interval . The values at the Fourier frequencies are marked by circles and dots. Note that, when the horizontal axis is wrapped around the circumference of the unit circle, the points at and coincide. Therefore, only one of them is included in the interval.

Figure 11.
The frequency response of the 17-point wrapped filter defined over the interval . The values at the Fourier frequencies are marked by circles.
Figure 11.
The frequency response of the 17-point wrapped filter defined over the interval . The values at the Fourier frequencies are marked by circles.

Figure 12.
The deviations of the logarithms of the index of UK domestic expenditure from an interpolated linear trend. The smooth trajectory, which has been synthesised from the Fourier ordinates of the data that fall in the interval , corresponds to the business cycle.
Figure 12.
The deviations of the logarithms of the index of UK domestic expenditure from an interpolated linear trend. The smooth trajectory, which has been synthesised from the Fourier ordinates of the data that fall in the interval , corresponds to the business cycle.

Figure 13.
The periodogram of logarithmic expenditure data of Figure 12.
Figure 13.
The periodogram of logarithmic expenditure data of Figure 12.

Figure 14.
The periodogram of the subsampled anti-aliased data with the parametric spectrum of an estimated AR(2) model superimposed.
Figure 14.
The periodogram of the subsampled anti-aliased data with the parametric spectrum of an estimated AR(2) model superimposed.

Figure 15.
The frequency response function of the Butterworth filters of orders and with a nominal cut-off point of radians .
Figure 15.
The frequency response function of the Butterworth filters of orders and with a nominal cut-off point of radians .

Figure 16.
The frequency response function of the Hodrick–Prescott low pass smoothing filter—or Leser filter—for various values of the smoothing parameter.
Figure 16.
The frequency response function of the Hodrick–Prescott low pass smoothing filter—or Leser filter—for various values of the smoothing parameter.

Figure 17.
The residuals from a linear detrending of the logarithms of the monthly U.S. retail sales from January 1953 to December 1964, with an interpolation of four years length inserted between the end and the beginning of the circularised sequence, marked by the shaded band.
Figure 17.
The residuals from a linear detrending of the logarithms of the monthly U.S. retail sales from January 1953 to December 1964, with an interpolation of four years length inserted between the end and the beginning of the circularised sequence, marked by the shaded band.

Figure 18.
The logarithms of annual U.K. real GDP from 1873 to 2001 with an interpolated trend. The trend is estimated via a filter with a variable smoothing parameter.
Figure 18.
The logarithms of annual U.K. real GDP from 1873 to 2001 with an interpolated trend. The trend is estimated via a filter with a variable smoothing parameter.

Figure 19.
The coefficients from a finite-sample Butterworth filter of order and with a cut-off frequency of . The filter is appropriate to a sample of points and the output is at .
Figure 19.
The coefficients from a finite-sample Butterworth filter of order and with a cut-off frequency of . The filter is appropriate to a sample of points and the output is at .

© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pollock, D.S.G. Filters, Waves and Spectra. Econometrics 2018, 6, 35. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics6030035
AMA Style
Pollock DSG. Filters, Waves and Spectra. Econometrics. 2018; 6(3):35. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics6030035
Chicago/Turabian StylePollock, D. Stephen G. 2018. "Filters, Waves and Spectra" Econometrics 6, no. 3: 35. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics6030035
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.