1. Introduction
Climate change caused by carbon emissions has resulted in global warming and created an increasing threat to the environment and survival of all living things on earth. To cope with this challenge, the Chinese government declared at the 2009 United Nations Climate Change Conference its goal to reduce the intensity of carbon emission by 40–45% below 2005 levels, by 2020. A low-carbon economy has been considered to be an effective development framework for carbon reduction and environmental protection without affecting economic enhancement [
1,
2]. As a significant part of economic development, the tourism industry is encouraging low-carbon tourism and developing low-carbon tourism destinations (LCTDs) [
3,
4]. Meanwhile, more and more tourists are paying attention to carbon reduction and environmental protection, and thus select low-carbon tourism destinations to relieve the mental pressure caused by their work. Therefore, in order to obtain a high-quality travel experience, it is important for tourists to select the best option(s) from multiple low-carbon tourism destinations based on multi-attributes while considering carbon reduction, lower energy consumption and environmental protection. Generally speaking, tourism destination selection often involves multiple tourists. Each tourist may have his/her own demands and may approach the selection process with different expectations, but all of these tourists have a mutual interest in reaching final agreement on selecting the best travel destination(s). On the other hand, it is difficult for the tourist group to create a ranking order of all possible tourism destinations due to the fact that the multiple attributes or criteria are frequently conflicting. To address such problems in selecting tourism destinations, this paper develops an approach to solve group decision-making problems, where evaluations of all of the alternatives with respect to each attribute are provided as linguistic terms, and the attribute weights are partly known.
Linguistic multi-attribute group decision making (MAGDM) uses linguistic terms in a linguistic term set (LTS) to express decision makers’ evaluations of alternatives with respect to each attribute. In order to aggregate such evaluation values into an overall value in the linguistic environment, Herrera and Martínez [
5] developed a 2-tuple linguistic representation model, in which a linguistic term in a balanced LTS is expressed by a linguistic 2-tuple. Wang and Hao [
6] devised another 2-tuple linguistic representation model, where trapezoidal fuzzy numbers are used to characterize semantic information of linguistic terms in an unbalanced LTS. Based on these two representation models, a number of aggregation operators have been developed to solve linguistic MAGDM problems, such as the weighted averaging operator [
5], the linguistic power aggregation operator [
7], the linguistic hybrid harmonic operator [
8] and the linguistic Choquet aggregation operator [
9]. However, attribute weight information may be incomplete because of the complexity and indeterminacy of MAGDM problems [
10,
11]. Some researchers have focused their attention on linguistic MAGDM with incomplete weight information. For instance, Wei [
12] developed another method to solve linguistic MAGDM problems, where linguistic terms are transformed into 2-tuples and TOPSIS (technique for order performance by similarity to ideal solution [
13]) is used to devise an optimization model for determining attribute weights. Wei [
14] proposed an approach to MAGDM, in which a maximizing-deviation-based optimization model is established to obtain attribute weights. Zhang and Guo [
15] put forward an approach to linguistic MAGDM with multi-granularity and incomplete attribute weight information. By using the positive and negative ideal solutions, Ju [
16] presented a method for solving linguistic MAGDM problems with incomplete linguistic weight information. In recent years, MAGDM with linguistic information has been widely used in many different areas, such as company performance assessment [
17], recommender systems [
18] and supplier selection [
19].
Decision-making methods have been applied in low-carbon economy development. Tong and Wang [
20] proposed a group decision-making framework with intuitionistic fuzzy preference relations and applied it to low-carbon supplier selection. Cho et al. [
3] adopted the fuzzy analytic hierarchy process to construct evaluation indicators of Taiwan’s low-carbon tourism development. Cheng [
3] used the Delphi method and the analytic hierarchy process to establish evaluation indicators of low-carbon tourist attractions. Zhang [
21] employed the analytic network process to evaluate regional low-carbon tourism strategies.
In real-life linguistic MAGDM problems, different decision makers often have various expectations and considerations for semantic scale values of linguistic terms, which can be characterized by their risk preferences [
22,
23,
24]. For example, if linguistic terms are used to describe the evaluation of a tourism destination’s low-carbon facilities, then different tourists may have various expectative scale values for the linguistic term “Good”. Zhou and Xu [
23] introduced two parameters reflecting risk preferences to extend the sigmoid function and proposed the notion of generalized linguistic term sets (GLTSs). Lin and Wang [
24] developed GLTSs with triangular fuzzy semantic information and put forward an approach to solve qualitative decision-making problems. In this paper, we establish an optimization model to obtain an optimal group GLTS based on individual decision maker’s risk preferences. By using the triangular fuzzy weighted average based aggregation method, individual linguistic evaluations are fused into group triangular fuzzy evaluations. Based on the group evaluation information, a linear program is established to obtain optimal attribute weights. A detailed procedure is developed to solve linguistic MAGDM problems with risk preferences and incomplete weight information.
The remaining contents of this article are organized as follows. The next section gives preliminaries on LTSs, GLTSs and the Euclidean distance of any two positive triangular fuzzy numbers.
Section 3 describes linguistic MAGDM problems and establishes a nonlinear programming model to obtain a group GLTS. A linear program and a procedure are developed for solving linguistic MAGDM problems with risk preferences and incomplete weight information in
Section 4.
Section 5 provides a case study of a low-carbon tourism destination selection problem in order to examine the proposed decision models. Finally,
Section 6 offers concluding remarks.
2. Preliminaries
This section offers preliminaries on LTSs, GLTSs and the Euclidean distance between two positive triangular fuzzy numbers.
Let
be an LTS, where
and
are two positive integers,
is the granularity of
, and
s0 is the neutral linguistic term in
, such as “middle”, “fair” and “indifference”. If
, then
satisfies the following characteristics [
25]:
- (i)
The set is ordered, i.e., if and only if ;
- (ii)
A negation operator can be defined as , where .
A LTS
is called a balanced LTS if
and the distribution of its semantic information is uniform and symmetrical; otherwise,
is an unbalanced LTS. For example, an LTS including seven linguistic terms (
) is expressed as:
In order to characterize semantic information with risk preferences for linguistic terms in a LTS, Lin and Wang [
24] introduced the following notion of a GLTS.
Definition 1 [24]. For an LTS , a GLTS is defined aswhere is a triangular fuzzy number with two parameters and (
)
and indicates a fuzzy semantic value of for each , and and are given as It is obvious that and for . If , then the risk preferences of semantic values of linguistic terms in are radical. If , then the risk preferences of semantic values of linguistic terms in are neutral. If , then the risk preferences of semantic values of linguistic terms in are aversive.
For any two positive triangular fuzzy numbers
and
, their Euclidean distance is given as [
26]
It is obvious that if and . According to (2)–(6), we have if and . This implies that the distribution of semantic values of linguistic terms in is symmetrical. In this situation, if is approximately equal to , i.e., for , then is said to have symmetry and approximate uniformity; otherwise, is symmetrical and non-uniform.
If and , then one has and there exists satisfying . This indicates that the distribution of semantic values of linguistic terms in is asymmetrical and non-uniform.
In order to compare and rank triangular fuzzy numbers, the following formula is used to obtain the score of a triangular fuzzy number
[
27].
3. An Optimization Model for Determining a Group Generalized Linguistic Term Set
This section describes an MAGDM problem and establishes an optimization model to obtain an optimal group GLTS.
Given feasible alternatives and m qualitative attributes . Let be the alternative set and be the attribute set, then an MAGDM problem is to determine a ranking of all alternatives or find the best alternative(s) from feasible alternatives in according to the evaluation information offered by a group of experts or decision makers denoted by .
Assume that the important weight vector of the experts is , where for each , and the weight vector is normalized to one, i.e., . In linguistic MAGDM, each expert uses linguistic terms in to evaluate the alternatives in X with respect to the attributes in and provides a decision matrix as , where is a linguistic term in , i.e., for .
In linguistic MAGDM with risk preferences, different experts have various expectations and considerations for the semantic scale value of a linguistic term. In other words, different decision makers have various risk preferences on providing their evaluation information. In order to aggregate individual evaluations into a group evaluation, it is necessary to determine a group GLTS based on the expected triangular fuzzy semantic values given by the decision maker for linguistic terms in .
Let
be the set of the expected triangular fuzzy semantic information provided by the decision maker
, then the following optimization model is devised to determine an optimal group GLTS.
where
is the Euclidean distance defined by (6) and
are decision variables.
Solving the above nonlinear programming model yields an optimal solution denoted by
and
. By plugging
and
into (3)–(5), we obtain an optimal group GLTS as
where
We can see from (9)–(12) that the optimal group GLTS captures and synthesizes individual decision makers’ risk preferences. If , then the expert group prefers to make a risk-seeking decision. If , then the expert group prefers to obtain a neutral-risk decision result. If , then the expert group prefers to make a risk-aversion decision.
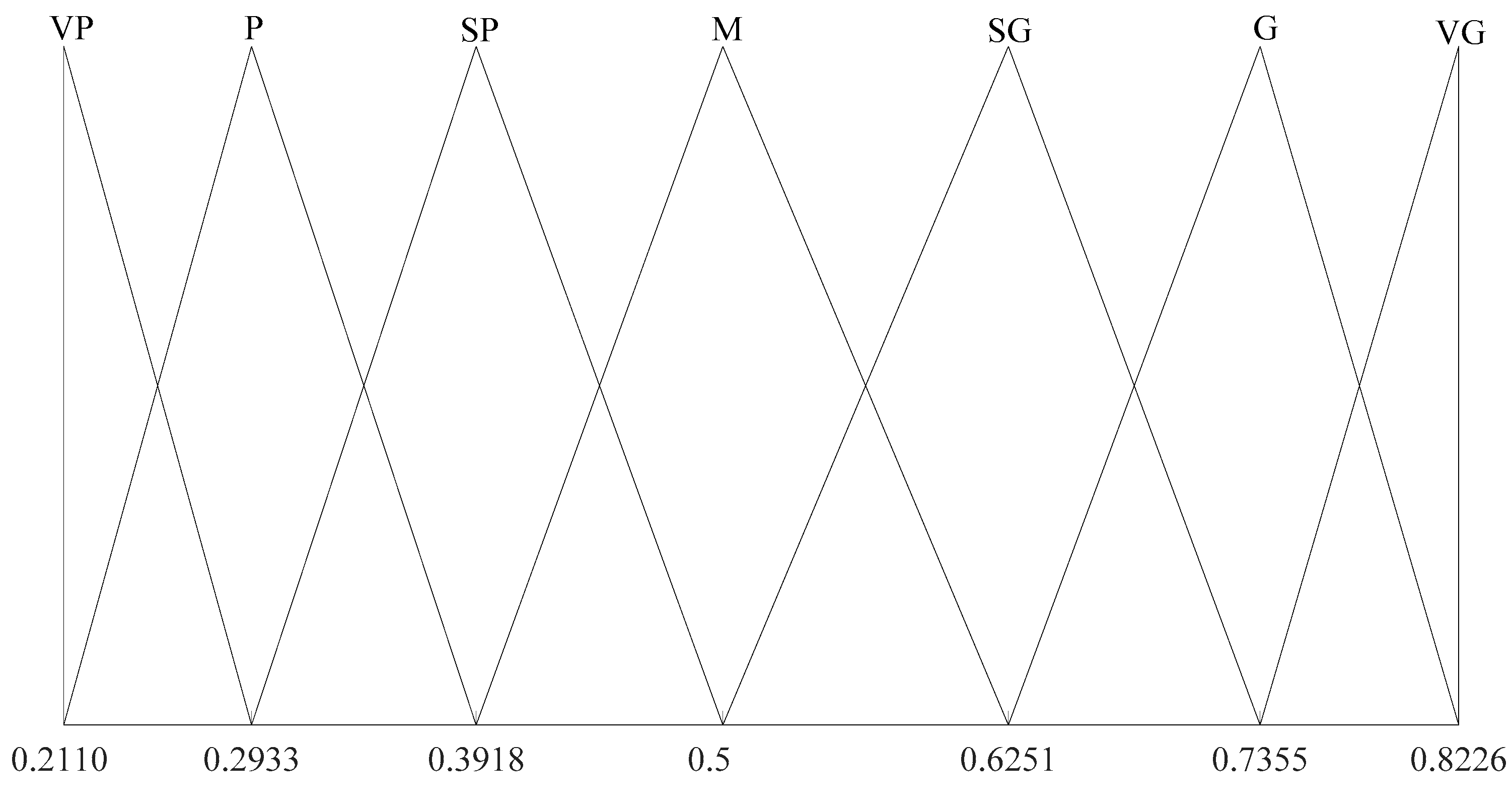
Example 1. Consider the LTS given by (1). Three decision makers and provide their expected triangular fuzzy semantic information as follows. Assume that the important weights of the three decision makers are 0.4, 0.4 and 0.2 respectively. By solving the optimization model (8), we obtain an optimal solution of
and
. Thus, as per (9)–(12), an optimal group GLTS is determined as
Obviously,
, indicating that
is a risk-seeking GLTS. The distribution of the semantic values of
is shown in
Figure 1 , where VP, P, SP, M, SG, G and VG are defined in (1). It is easy to verify that
and there exists
satisfying
. Hence, the distribution of the semantic values of
is asymmetrical and non-uniform.
4. An Approach to Linguistic MAGDM with Risk Preferences and Incomplete Weight Information
This section uses the triangular fuzzy weighted average based aggregation method to fuse individual linguistic evaluations into a group triangular fuzzy evaluation and develops a linear program to obtain optimal attribute weights. A procedure is also devised for solving linguistic MAGDM problems with risk preferences and incomplete weight information.
Once a group GLTS
is determined, each linguistic-term-based decision matrix
(
) can be transformed into a triangular fuzzy decision matrix denoted by
where
Based on the triangular fuzzy decision matrices
(
), using the triangular fuzzy weighted average operator together with the decision makers’ weight vector
yields a group triangular fuzzy decision matrix as
where
In MAGDM problems, it is clear that different attribute weights reflect their importance in selecting the best alternative and ranking alternatives. Let
be the attribute crisp weight vector, where
and
,
. If the attribute weights in
are completely known, then from the group decision matrix
, a group overall evaluation value of alternative
is determined as
for
.
In reality, it is often difficult for decision makers to offer exact values for attribute weights due to the complexity of practical decision cases and the limitation of the decision makers’ knowledge. Thus, the attribute weight information may be incomplete or partially known, which can be characterized by a nonempty subset of all combinations of the following five forms.
- (i)
A weak ranking: ;
- (ii)
A strict ranking: , where ;
- (iii)
An interval form: , where ;
- (iv)
A ranking with multiples: , where and
- (v)
A ranking of deviations: , where .
Since the value defined by (18) indicates the overall evaluation of alternative , the larger the triangular fuzzy number , the better the alternative is. Thus, as per the score of a triangular fuzzy number given by (7), we should find a weight vector such that is maximized for all . Therefore, the following multi-objective optimization model is established to determine attribute weights.
Since each alternative
is a feasible and non-inferior alternative and the maximization problems
(
) have the same constraint conditions, the multi-objective optimization model (19) can be converted into the following aggregated optimization model by setting the same important weight for each goal
(
).
As per (7) and (18), the optimization model (20) can be equivalently rewritten as the following linear program.
where
is a decision variable for all
.
By solving the linear program (21), we obtain an optimal attribute weight vector denoted by .
Substituting
into (18) yields an optimal group overall evaluation value of alternative
as
Based on the aforementioned analysis, a procedure is now developed for linguistic MAGDM with risk preferences and incomplete attribute weigh information.
Procedure
Step 1: Each decision maker () adopts linguistic terms in to evaluate alternatives in X with respect to each attribute in , which are given by a decision matrix and provides his/her risk preference information .
Step 2: Obtain an optimal group GLTS by solving the optimization model (8) and using (9)–(12).
Step 3: Transform the linguistic-term-based decision matrix into a triangular fuzzy decision matrix as per (14) and (15) for each .
Step 4: Aggregate individual decision matrix () into a group triangular fuzzy decision matrix according to (17).
Step 5: Determine optimal attribute weights by solving the linear program (21).
Step 6: Employ (22) to obtain optimal group overall evaluation values () for all alternatives in .
Step 7: Use (7) to calculate scores ().
Step 8: Obtain a ranking order of all alternatives in terms of the decreasing order of the scores (), and is employed to express that alternative is preferred to .
5. A Case Study of the Low-Carbon Tourism Destination Selection Problem
This section applies the proposed linguistic MAGDM model to examine a low-carbon tourism destination selection problem.
With the continuing advocacy and promotion of the Chinese government, many tourism destinations have been developed to reduce carbon emissions and save energy. Moreover, many tourists have recognized the importance of low-carbon tourism for environmental protection. In order to find a good balance between the enjoyment of a trip and carbon emission reduction, it is crucial for tourists to compare and evaluate some known low-carbon tourism destinations, and then choose the best one(s) from these options. Generally speaking, this evaluation and selection process is based on several criteria or attributes. In this case study, the attributes consist of the following five aspects:
- (i)
: Low-carbon transportation, low-energy consumption vehicles and pick-up and drop-off services as reflected in connecting different scenic sites and reaching the destination.
- (ii)
: Food service including green food, a low-carbon environment and low-energy waste handling mechanisms.
- (iii)
: Hotels and accommodation, as reflected in green-material labels, low-carbon facilities and a low-carbon environment and education management.
- (iv)
: Consumption satisfaction, as reflected in the service cost of travel agencies, ticket prices for scenic sites and the cost of accommodation.
- (v)
: Attraction and impact of scenic sites, including low-carbon customer service and low-carbon management and control.
Without loss of generality, assume that three tourists (i.e., decision makers)
and
want to go on a low-carbon trip and their importance weights are 0.4, 0.4 and 0.2, respectively, i.e.,
. After preliminary screening there are four low-carbon tourism destinations
and
as the alternatives. Based on the LTS
S given by (1), the three tourists provide their linguistic evaluations for the four tourism destinations with respect to each attribute
(
). The three tourists’ linguistic evaluations are shown in
Table 1,
Table 2 and
Table 3, respectively.
Based on the expectations of semantic scale values of linguistic terms in
, the expected triangular fuzzy semantic values for the three tourists are as follows:
Solving the nonlinear programming model (8) yields an optimal solution of
. By (9)–(12), an optimal group GLTS is obtained as
According to (14) and (15), the decision matrices
(
) are converted to triangular fuzzy decision matrices
(
), which are shown in
Table 4,
Table 5 and
Table 6, respectively. As per (17), a group triangular fuzzy decision matrix
is determined as listed in
Table 7.
Assume further that the three tourists provide their incomplete attribute weight information as
Thus, based on (21), a linear program is established as
Solving (23) yields an optimal attribute weight vector as
.
As per (22), the optimal group overall evaluation values are determined as follows.
Using (7), we obtain , , and .
Since , the four low-carbon tourism destinations are ranked as and thus, is the best low-carbon tourism destination.
Next, a study is made to compare the attribute weight vector and the ranking order obtained from the proposed model herein with the results derived from the 2-tuple linguistic based approaches by Wei [
12,
14] and Ju [
16].
Wei [
12] first converted individual linguistic-term-based decision matrices to 2-tuple linguistic decision matrices, which are then aggregated into a group decision matrix. Based on the TOPSIS method, Wei [
12] developed an optimization model to obtain an optimal attribute weight vector. For this case study, using this optimization model yields the optimal attribute weight vector as
and a ranking order of the four low-carbon tourism destinations is determined as
. The results are shown in the second row in
Table 8.
Wei [
14] used the maximizing deviation method to establish an optimization model for determining an optimal attribute weight vector and employed grey relational analysis to obtain a ranking order of all alternatives. Using this maximizing deviation based model generates the optimal attribute weight vector as
and thus, a ranking order of the four low-carbon tourism destinations is obtained as
. The results are listed in the third row in
Table 8.
Ju [
16] aggregated individual 2-tuple linguistic decision matrices into a group decision matrix whose symbolic translation values belong to
and constructed a TOPSIS-based optimization model to obtain an optimal attribute weight vector. By using Ju’s approach [
16], we obtain the optimal attribute weight vector as
and the ranking order of the four low-carbon tourism destinations as
, which are shown in the penultimate row in
Table 8.
Table 8 reveals that the ranking order obtained by the proposed model in this paper differs from the results derived by the 2-tuple linguistic based approaches in [
12,
14,
16]. This difference is mainly due to the fact that the 2-tuple linguistic based approaches [
12,
14,
16] adopt symbolic translation models to obtain a group decision matrix and do not consider decision makers’ risk preferences for semantic scales of linguistic terms. As a result of this treatment, the importance weight of attribute
is determined to be 0. In other words, when the linguistic MAGDM methods [
12,
14,
16] are applied in solving this low-carbon tourism destination selection problem, the evaluation criterion
is excluded from the consideration. It can be seen from
Table 8 that by our proposed model,
is determined to be a pivotal criterion for the low-carbon tourism destination selection.
6. Conclusions
In this paper, a nonlinear programming model has been established to obtain an optimal group GLTS based on individual risk preferences. An aggregation method has been presented to fuse individual linguistic-term-based evaluation values into a group evaluation with triangular fuzzy information. By maximizing the score of the group overall evaluation value for each alternative, a multi-objective optimization model has been devised and converted into a linear program for determining an optimal attribute weight vector. An approach has been developed for linguistic MAGDM with risk preferences and incomplete weight information. A low-carbon tourism destination selection case study has been provided to demonstrate the use of the proposed group decision-making model.



{kind=link}