Overlay Analysis
Overlay analysis is the simplest form of spatial modeling, and consists of stacking different thematic maps on top of one another. This method was employed by Lindley
et al. [
7] to consider conurbation-scale risk and adaptation assessment methods to study the response of the greater Manchester urban area to climate change. This new, explicitly spatial method was developed to address the lack of information needed to adapt to climate change.
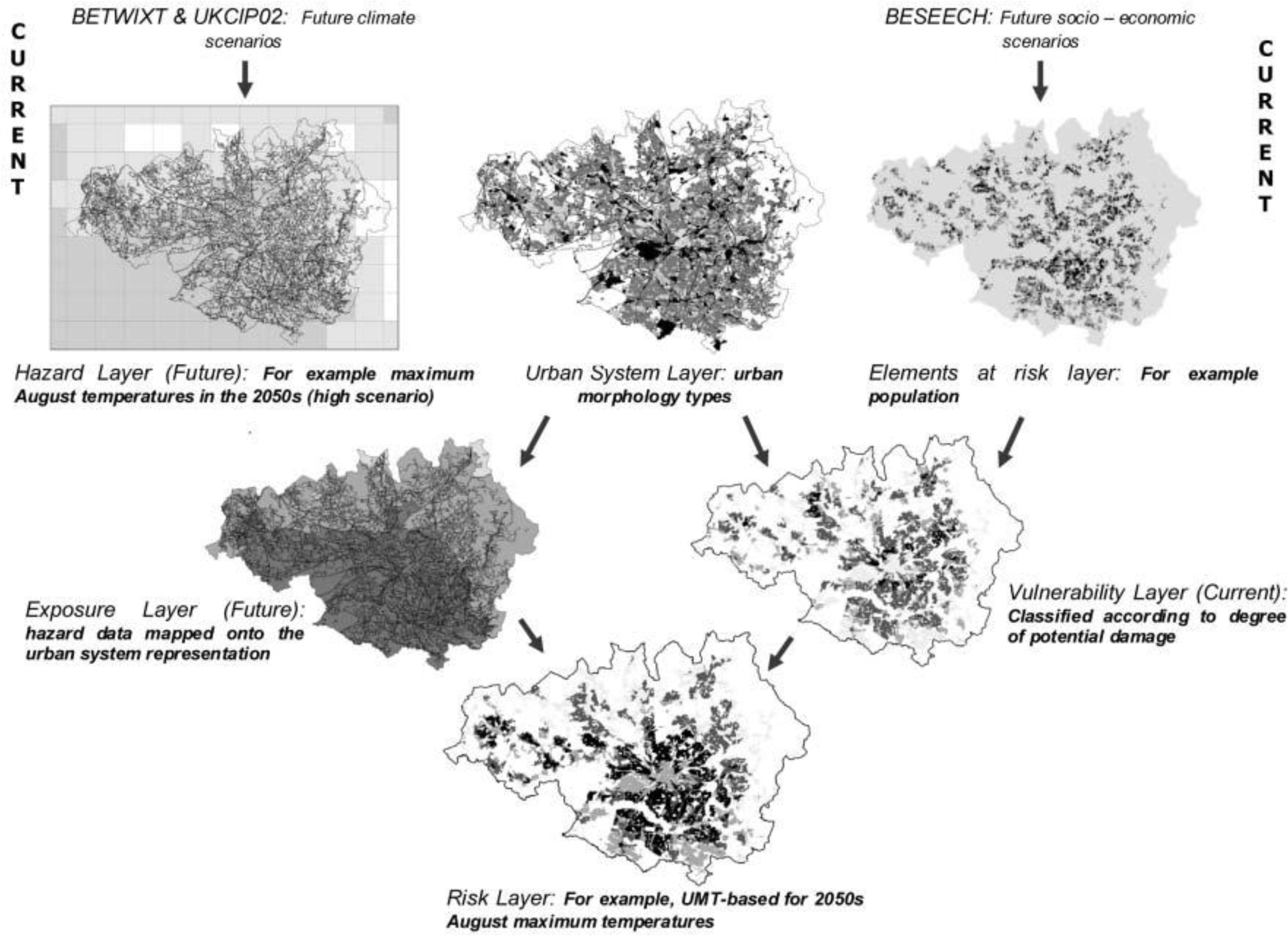
Conurbation-scale risk assessment was performed to evaluate an entire urban-system as well as provide a basis for neighborhood-level analyses. Similar to the conceptual framework introduced earlier, the authors defined risk to be an interaction between hazard, exposure, and vulnerability. This methodology uses GIS to create separate maps of various risk elements (
i.e., population), hazards (
i.e., maximum August temperatures), and the urban-system (
i.e., urban morphology types). A layer that maps the current vulnerability of the region is then created by merging the risk element layers to the urban-system layer, and a layer that projects future exposure is created by merging the hazard layer to the urban-system layer. Finally, the projected exposure layer and current vulnerability layer are merged to create a final risk layer (see
Figure 2).
To demonstrate the method, the authors used conurbation-scale risk assessment to analyze how socio-economic change will affect the risk of heat stress (see
Figure 3). This case study led the authors to make several policy suggestions that could help mitigate overall risk to heat stress in the Greater Manchester area, UK. To increase an individual’s personal adaptive capacity, the authors propose longer working lives to provide health coverage and to create stronger social networks. Additionally, the authors recommend urban densification and an improved transport system so that the region can grow without increasing social deprivation. Finally, the authors encourage increased greenspace cover to reduce the heat hazard.
The authors reported this methodology to be valuable for several reasons. Firstly, since each risk element is represented as a separate layer, it is possible to modify each element individually to re-assess the final risk layer. This allows planners to easily evaluate different adaptation strategies to determine how best to mitigate the risk faced by urban areas due to climate change. Secondly, by developing this GIS method it is possible not only to identify current areas where adaptation is most necessary to deal with the risks posed by climate change, but also possible to identify areas that are most at risk in the future. Finally, to perform the conurbation-scale risk assessment, the authors used previously generated data to create the various GIS layers. By using the best available data, it was possible to produce results rapidly, which will become increasingly necessary in order for urban areas to adapt swiftly to climate change.
By employing conurbation-scale risk assessment, the authors demonstrated the usefulness of visualization and cartographic overlay. This assessment is efficient and can be completed relatively quickly since it utilizes the best available spatial data rather than creating new data. It also allows researchers to easily compare various risk scenarios to discern the proper adaptive approach to climate change.
Other research uses overlay analysis to identify areas of environmental justice concern. Environmental justice occurs when a certain social group is disproportionately impacted by harmful land uses. This has become an increasingly important topic in the study of health disparities. Researchers have recently sought answers to the health risks of residential racial segregation. In the paper titled
Separate and Unequal, authors Morello-Frosch and Jesdale implement a GIS model across the US to examine area-level factors, racial segregation, and estimated cancer risk associated with exposure to ambient air pollution [
8]. While poverty can be intertwined with racial segregation, there is an independent relation between racial segregation and disparities in exposure to harmful pollutants. This analysis has expanded the idea of segregation through the exploration of several different racial/ethnic groups and the thoughtful adjustment for factors confounding racial inequality.
Autocorrelation
First we will discuss methods for assessing autocorrelation among observations. Tobler’s [
9] oft-cited first law of geography captures the essence of spatial autocorrelation: “everything is related to everything else, but near things are more related than distant things”. In other words, spatial autocorrelation means attribute values (say mortality) of proximal entities (say metropolitan areas) will likely be more clustered or share similar values than distant ones. This is similar to time series data where we would expect to see mortality rates, for example, that are one day apart to be more similar than mortality rates three months in the future. Although similar, spatial autocorrelation tends to be more complex than serial autocorrelation in time series. First, temporal processes can only move in one direction (
i.e., from present to future), whereas spatial processes are two-dimensional (
i.e., involve area and direction around a compass). They may also have a third dimension (e.g., the area and depth of a ground water aquifer). Second, the metric used to measure distance can vary (e.g., Euclidian distances or functional distances such as travel time or monetary cost) [
10]. Thus the two factors, dimensionality and functional distance, make analysis of spatial autocorrelation more complex to model than its temporal counterpart.
Using ambient air pollution as an example, we might expect pollution levels to be more similar between Pittsburgh and Johnstown (a nearby city) than between Pittsburgh and Seattle. This may occur because of similarities in the underlying social and economic processes that cause pollution (e.g., manufacturing base) or atmospheric processes that suspend pollutants over large distances and disperse pollutants from region to region (e.g., prevailing wind patterns). Usually the level of spatial autocorrelation would diminish as a function of distance between the two regions, unless there is some reason for similarity due to industrial structure or some other factor associated with the pollution phenomenon such as transportation emissions. Autocorrelation tests use point, line, or area features that have attribute values attached to them. One important distinction in these tests is whether they measure global or local autocorrelation.
Global autocorrelation tests measure the tendency, across all data points, for higher (or lower) values to correlate more closely together in space with other higher (or lower) values than would be expected if the data points were drawn from a random distribution. Several tests of global autocorrelation are available, with the Moran’s I being the most common. Positive values of the Moran’s I [
4] with significant p-values (
i.e., p < 0.05) suggest high values in region i tend to depend on values in adjacent regions j (
i.e., higher values will cluster in space with other high values). Negative values would suggest that high values tend to associate with low values, similar to a checker board pattern. To understand how autocorrelation tests work, it is useful to distinguish spatial autocorrelation from ordinary correlation. Autocorrelation is defined for observations lagged in time or space with a single sequenced variable, whereas ordinary correlation refers to the joint observation of two or more variables [
11]. In global tests for autocorrelation, it is assumed that the relationship between nearby or otherwise connected observations will remain the same everywhere in the study area (referred to as “stationarity” or “structural stability”). For example, the spatial autocorrelation between mortality rates in metropolitan areas of the United States would be the same at all places in the country, meaning the relationship between the areas was purely a function of distance between the areas and not relative location. A positive autocorrelation suggests that like values tend to be located nearby one another.
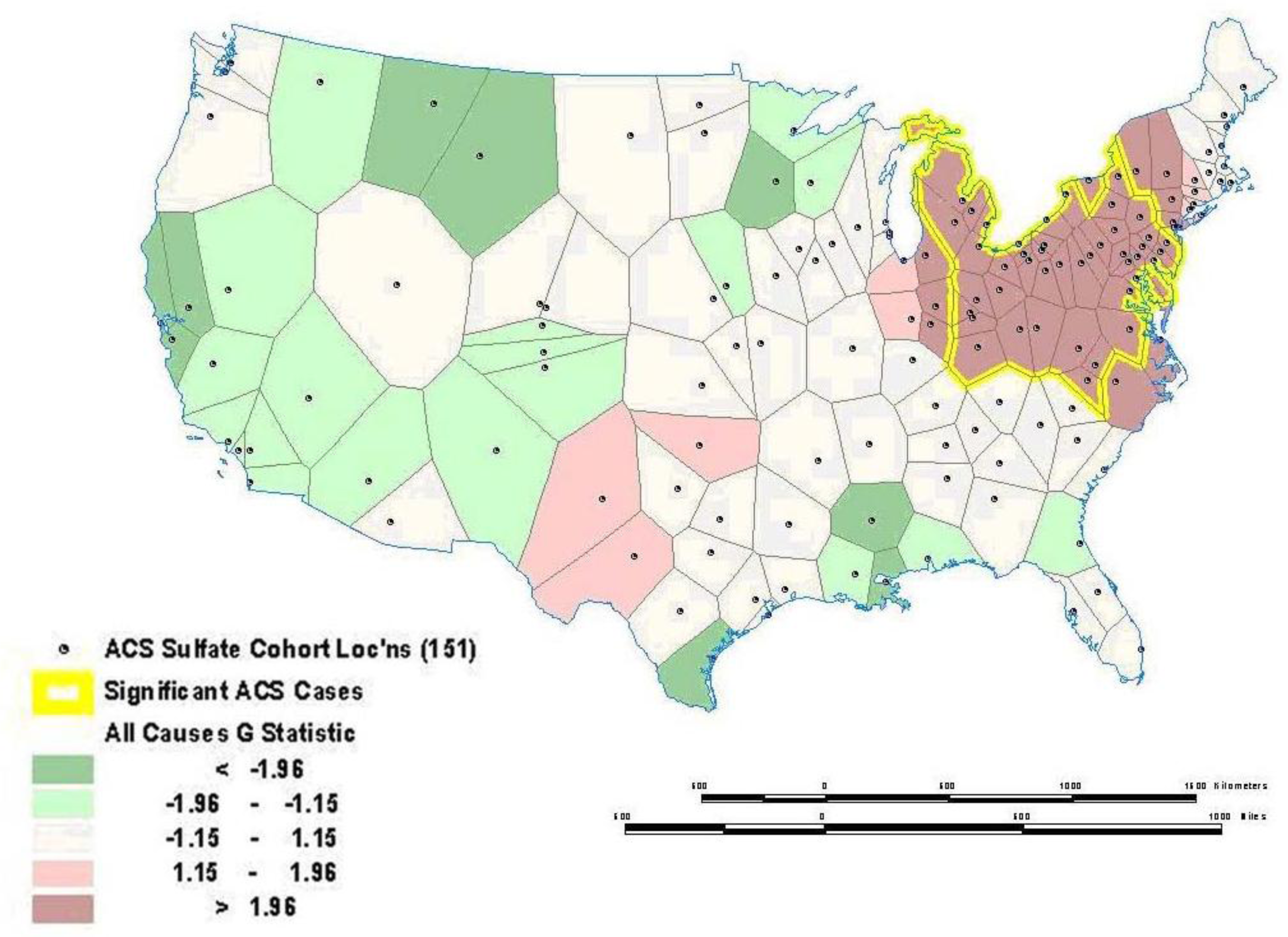
Sometimes global relationships are of less interest than local relationships or clusters that may display non-stationarity. Local indicators of spatial association (LISA), such as the local Getis-Ord (G) and local Moran’s I statistics, can assess clustering in small areas to identify clusters or “hot spots” of high or low values (see [121–126] for computational details). These local statistics usually break the study area into smaller regions to determine if local areas have attribute values that are higher or lower than would be expected based on the global average or a random expectation for the entire study area. Using the G statistic to investigate mortality in the American Cancer Society (ACS) Cancer Prevention II Study in 1982 on approximately 550,000 subjects followed for vital status until 1989, we found a significant mortality cluster in the lower Great Lakes area (see
Figure 4) [
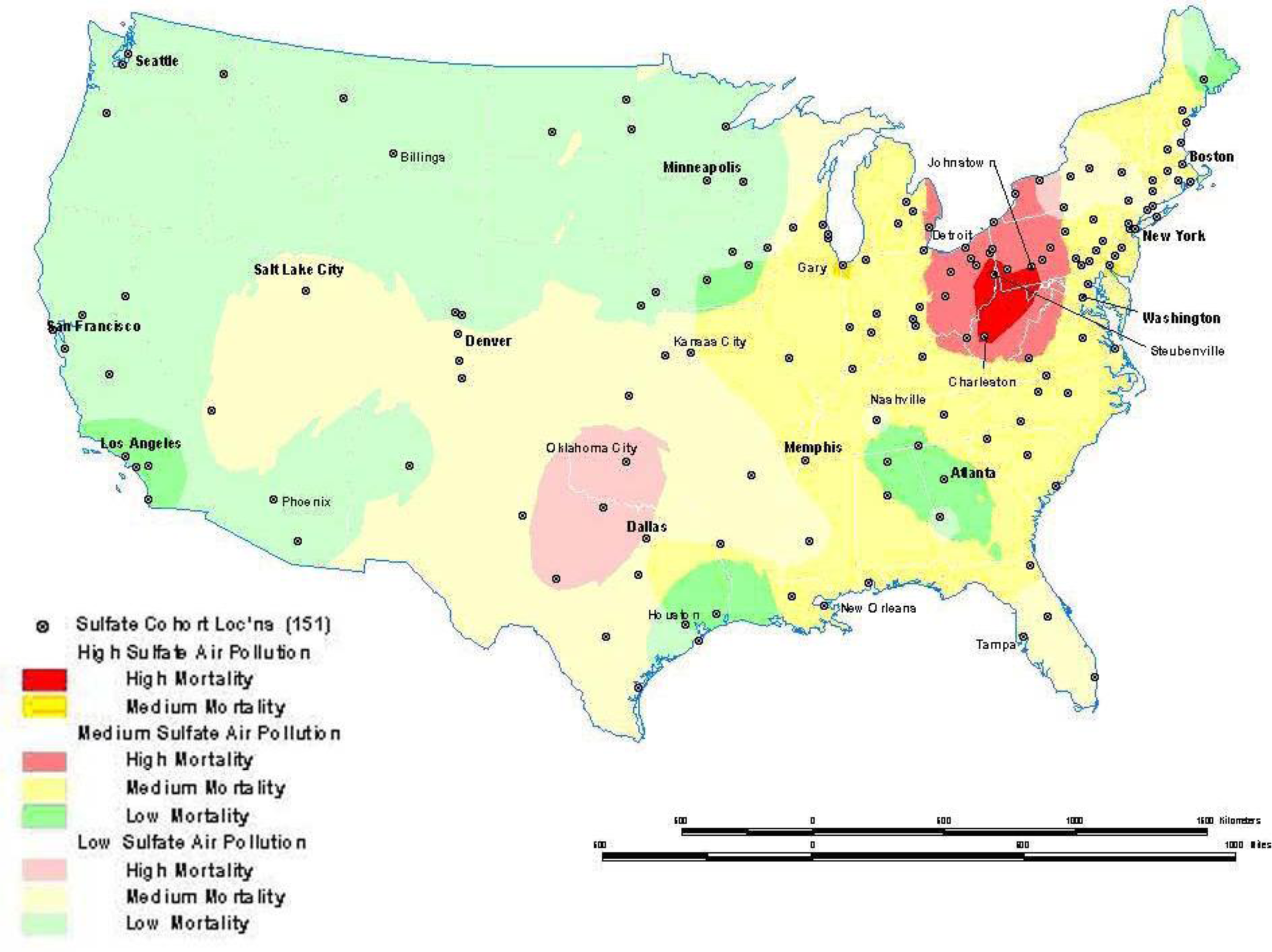
17]. This corresponds roughly to the high mortality-high pollution area shown in
Figure 5.
A major issue in the assessment of global or local spatial autocorrelation is the selection of a “spatial weights” or “connectivity” matrix. To assess autocorrelation, it is necessary to assign a matrix that formalizes the potential for spatial dependence. The simplest form of connection is the nearest neighbor approach using a series of polygons such as the census tracts in
Figure 6 [
18]. With this approach, we would assign a value of one for those neighbors that are connected to each other (
i.e., shared a boundary) and a value of zero for those that did not have a connection. The other way to define the weights matrix is with distance. Most distance matrices rely on Euclidian distance, although many modifications are possible if there is prior knowledge about the spatial process in question (e.g., travel time instead of straight line distance). To assign a more complex and realistic spatial weights matrix, it is essential to have prior knowledge about the processes that may have generated the spatial autocorrelation (e.g., population exchanges between cities based on commuting flows may result in a shared exposure to a harmful environmental contaminant and resulting higher mortality rates). Unfortunately, this information is often lacking, so spatial analysts must resort to some arbitrary spatial weight matrix such as the nearest neighbor or Euclidian distance. Other methods are available to assist with selecting an appropriate distance [
19]. In the absence of prior information to define the weighting matrix, sensitivity analysis using different weight matrices can be used. If autocorrelation is robust to different assumptions about the connections between places, we have stronger evidence that the results of the autocorrelation tests reflect some real effect and are not an artifact of the assumptions made about spatial dependence in the weight matrix.
Other methods can examine more than one type of event and multiple confounding variables at once, yielding a more informative control for confounding and assessment of autocorrelation. The generalized linear mixed models, generalized additive models (GAM), and Bayesian models are some techniques that allow for adjustment of spatial confounding (e.g., residential clustering by age and race) [
4]. As applied to the above example, these approaches would enable the study to assess the effect of pollutant exposure and control for other confounding variables such as age or smoking status.
In an example from the literature, Webster,
et al. [
21] use a GAM to examine the spatial distribution of breast cancer cases in Cape Cod, MA, and determine if there is clustering of the disease. The GAM was applied to case-control data to minimize spatial confounding as well as the bias that arises from mapping diseases with long latency periods [
21]. To map the cancer distribution on Cape Cod, Webster
et al. condition on several variables including residential history, age and race.
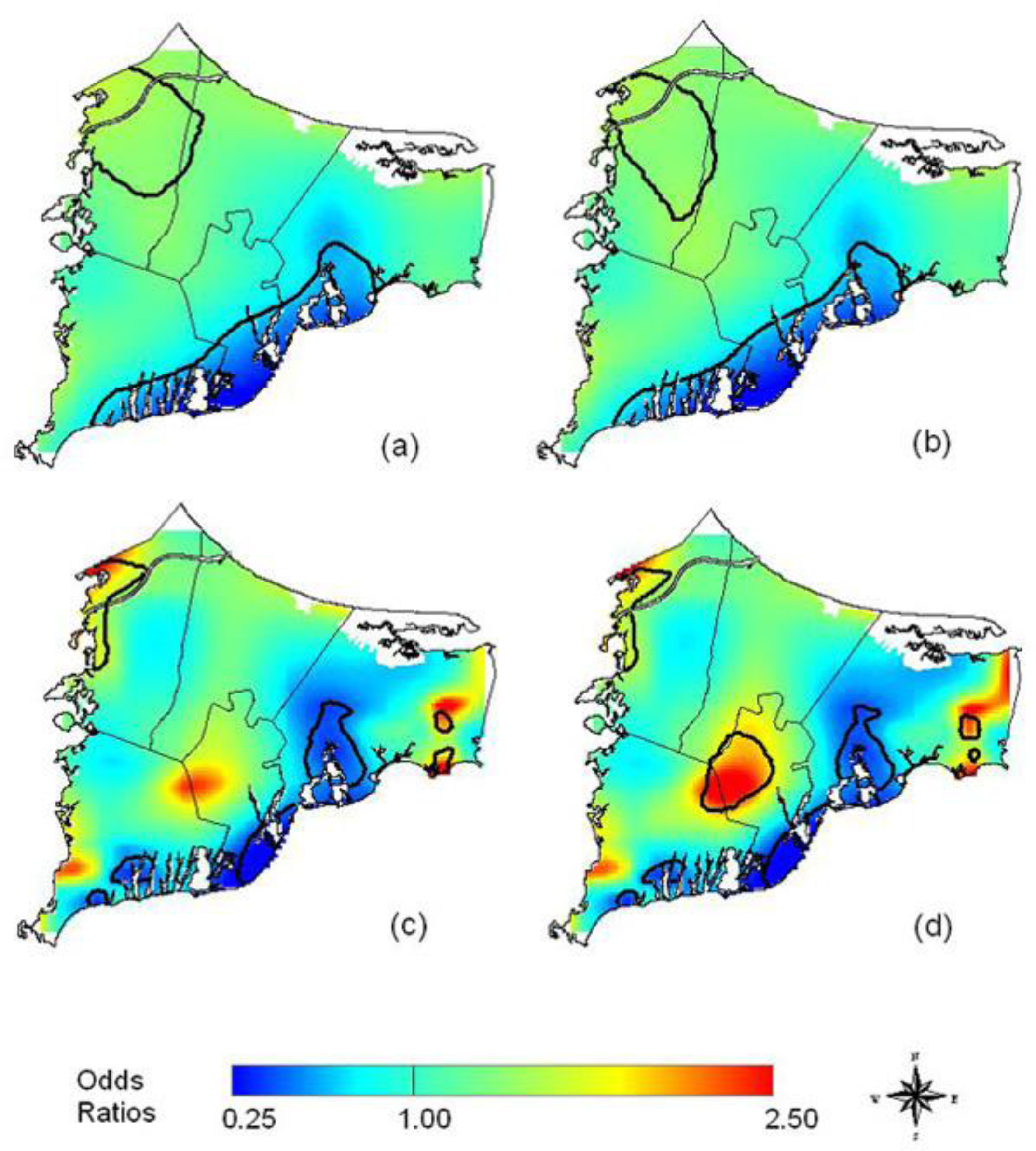
Figure 7 illustrates (a) the crude, unadjusted odds ratios (OR) with a span or smooth function of 35% of the data, (b) the adjusted model with race, (c) the crude ORs with a 15% span, and (d) the adjusted model showing spatial confounding by race with a 15% span.
Interpolation
Interpolation is a process whereby known data points are used to infer values over a space between the points to create a continuous surface. For example, data from a network of pollution monitoring stations may be interpolated to estimate the most likely values between sample locations. There are several different types of interpolation, including kriging, inverse distance weighting, splining and Thiessen polygons [
4]. Although such models are often used to predict likely values for exposure assessments, they can also form the basis of visualizing spatially continuous data. For example,
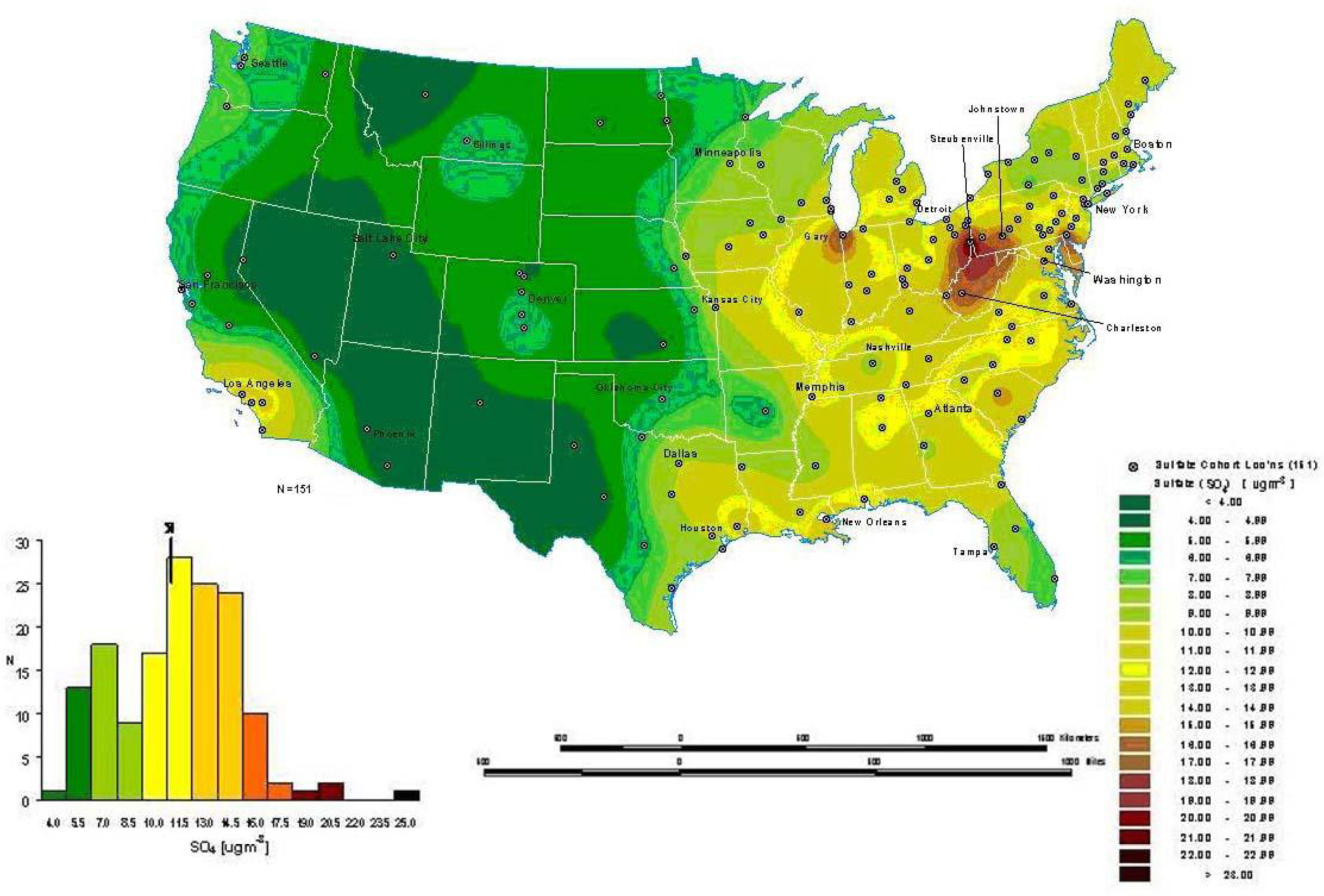
Figure 8a for the ACS study shows interpolated concentrations of ambient sulfates from fixed pollution monitors in 151 metropolitan areas of the United States. The high sulfate values in the lower Great Lakes region show a similar spatial distribution to the mortality rates in
Figure 6. This pollution surface is the same one used to generate
Figure 5. Some limitations to interpolation methods are the smoothing of local trends, the assumption that the surface is continuous, and that there are enough data points to make a valid prediction of the surface (
i.e., lower accuracy with fewer data points).
A special type of optimal interpolation known as “kriging” can be used to generate predicted values and their standard errors. These standard errors show where the interpolation tends to be less reliable. Kriging models exploit spatial dependence in the data to develop smoothed surfaces. The spatial dependence can be divided roughly into two broad categories. First-order effects measure broad trends in all the data points such as the global mean, whereas second-order effects measure local variations at shorter distances between the points [
4,
22]. Kriging models are considered optimal interpolators because they supply the best linear unbiased estimate (BLUE) of the variable’s value at any point in the study area [
22].
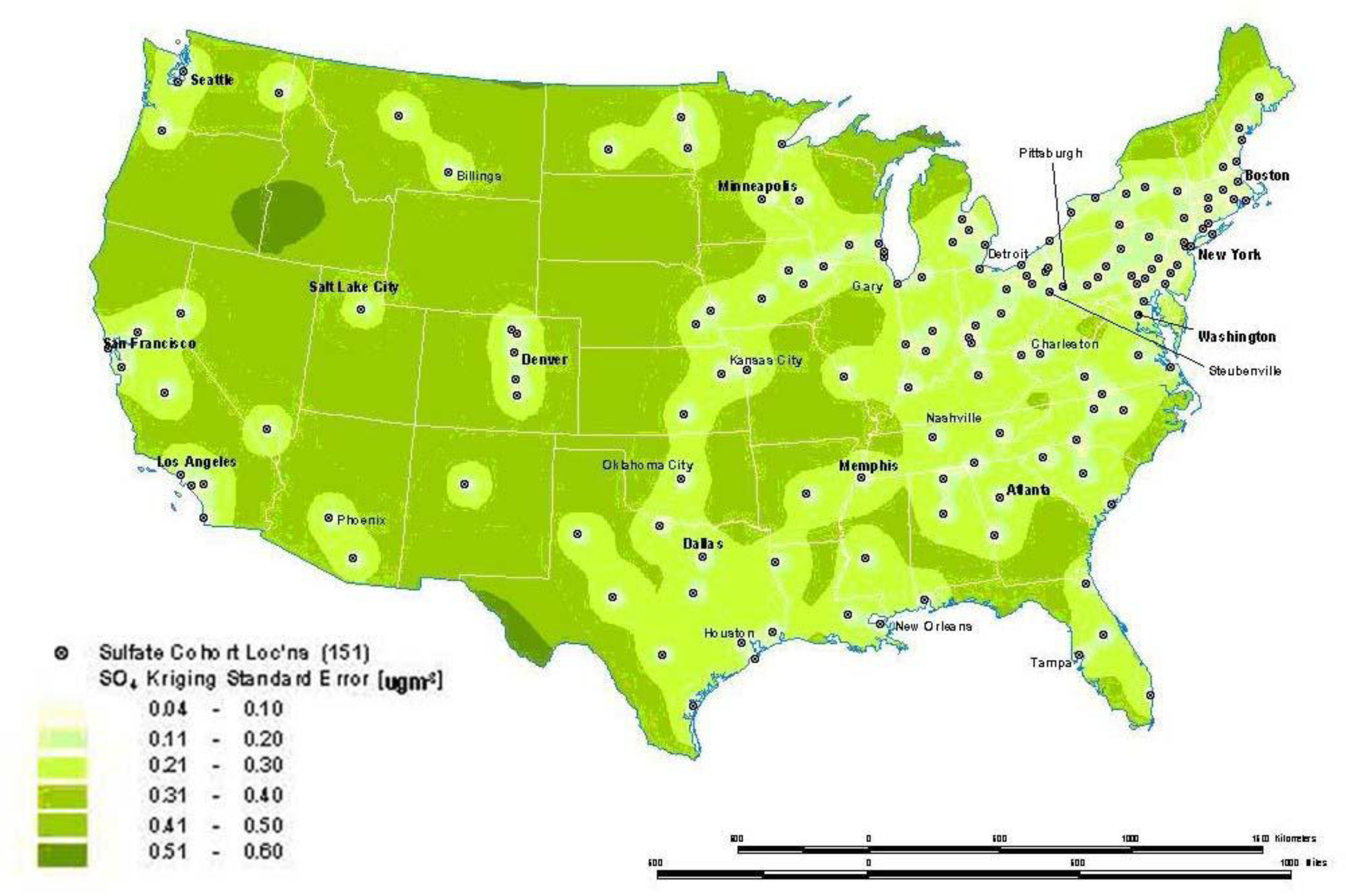
Figure 8b shows the standard errors of the interpolated sulfate surface of
Figure 8a. From this map, we can see that estimates are more reliable in areas where the cities with monitoring stations are denser, especially in the Northeast and Midwestern regions. Errors in the estimates are not often shown with interpolations, and this can lead to incorrect interpretations. In addition, it must also be kept in mind that the data set will determine the results. The sulfate pollution maps shown here depict spatial variation in the ACS sample of 151 metropolitan areas and are not necessarily representative of the spatial pattern that would be found for all the United States in a more complete sample.
Point Patterns
A third type of modeling deals with the intensity of point patterns over space. This type of modeling addresses the hypothesis that the intensity of point clustering in a given area differs significantly from a random (or control) pattern observed in the entire study area [
23,
24]. The concern here is with the location and the presence or absence of a disease or condition. For example, we might investigate the clustering of a specific disease known to be linked to an environmental contaminant. This helps identify disease or mortality clusters that may appear in proximity to a pollution source or some other potential risk factor. One major limitation of point pattern models arises from the nature of the data. Point events by definition carry one dimensional information about the event (usually disease or death at that location) which cannot be adjusted easily for other confounding factors such as age. Given the important role age plays in health and survival experience, this is a major shortcoming. Though cluster analyses are an example of the autocorrelation of related points that can display disease patterns as well as exposure patterns and facilitate identification of environmental justice sites.
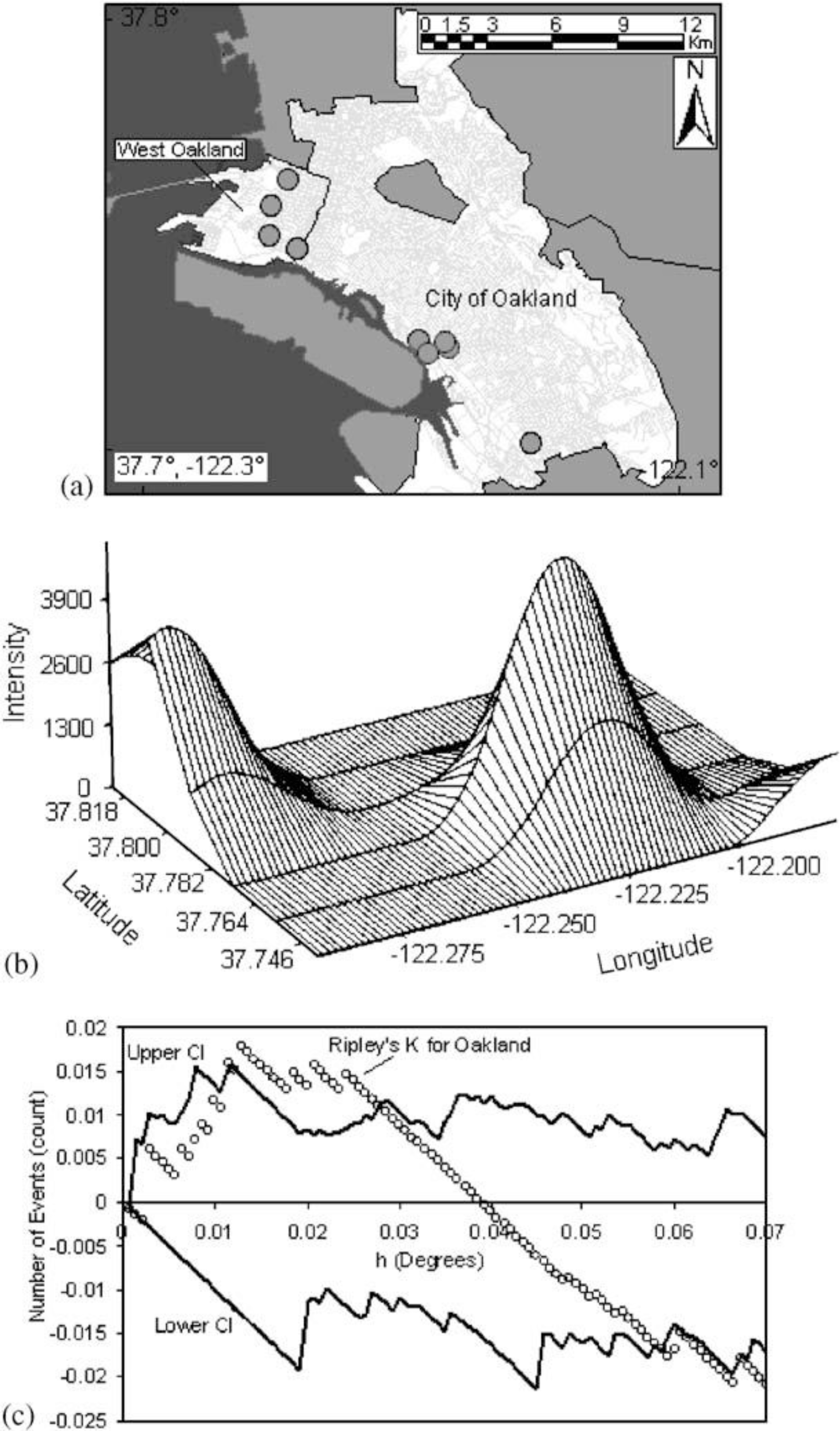
Figure 9, taken from Fisher,
et al. [
25] shows point intensity estimates of Environmental Protection Agency (EPA) designated Toxic Releases Inventory (TRI) facilities in the San Francisco Bay Area. With three different spatial scales—regional, countywide, and citywide—the researchers evaluate the density of TRI sources and whether the clusters are statistically significant with a first-order intensity distribution and a second-order Ripley’s K function. Ripley’s K is a method that compares a given distribution of points to a homogeneous Poisson distribution that is characterized by complete spatial randomness (CSR). Deviations from CSR can then be evaluated for significance. Ripley’s K calculates the relative distance between points by forming circles around randomly chosen points, and estimates the average number of points per unit area. Then the function compares the observed estimate to an expected estimate that is based on CSR.
At the regional level, Fisher
et al. [
25] found many clusters in the whole San Francisco Bay Area with two large, statistically significant peaks in the East Bay. Further, at the county level, there was statistically significant clustering along the western portion of Alameda County. The researchers then used the city-wide data to identify West Oakland as a TRI source cluster and confirm their hypothesis that West Oakland is an environmental justice site because it has a statistically significant clustered distribution of TRI facilities.
Figure 9b shows the location of the TRI clusters calculated with the intensity function, and
Figure 9c illustrates that the city-wide cluster is outside of the random Poisson distribution or CSR envelope (represented by the upper and lower solid lines). The researchers go on to integrate social and economic characteristics from the census to explore other area-level demographics that make West Oakland an area for environmental justice concern.
For certain types of disease analysis point pattern analysis can provide useful insights (e.g., the incidence of asthma among young adults 20−44 years old). Data for this example came from a respiratory health survey administered in 1993−94 [
17]. Recently developed methods and software are available to interpolate point patterns into continuous surfaces [
1]. In addition, it is possible to perform a point pattern analysis with multiple variables using a cross K-function [
4]. With these methods, a regular lattice of points or the centroids of some existing lattice such as census tract centroids serves as the vehicle of aggregation. A buffer of a given distance, for example 1.5 km, is drawn around each point in the lattice. Within this buffer there will be a certain number of sampled cases (e.g., young adults 20−44 years old, some of whom will probably have asthma). A rate of asthma is then calculated based on the ratio of cases to the total sample (say, 30 cases over 100 sampled or a rate of 300 per 1,000). The rates are then interpolated by a linear contour, with the result being a continuous surface of disease. Monte Carlo simulation is then used to assess statistical significance. With this simulation, each case is given an equal probability of having asthma and the point pattern is simulated many times (in this case 1,000) to generate a randomized surface. Rates for this surface serve to assess significance. If 950 of the 1,000 simulated surfaces have rates less than the one observed, we can say we are 95% confident that this rate could not have occurred by chance.
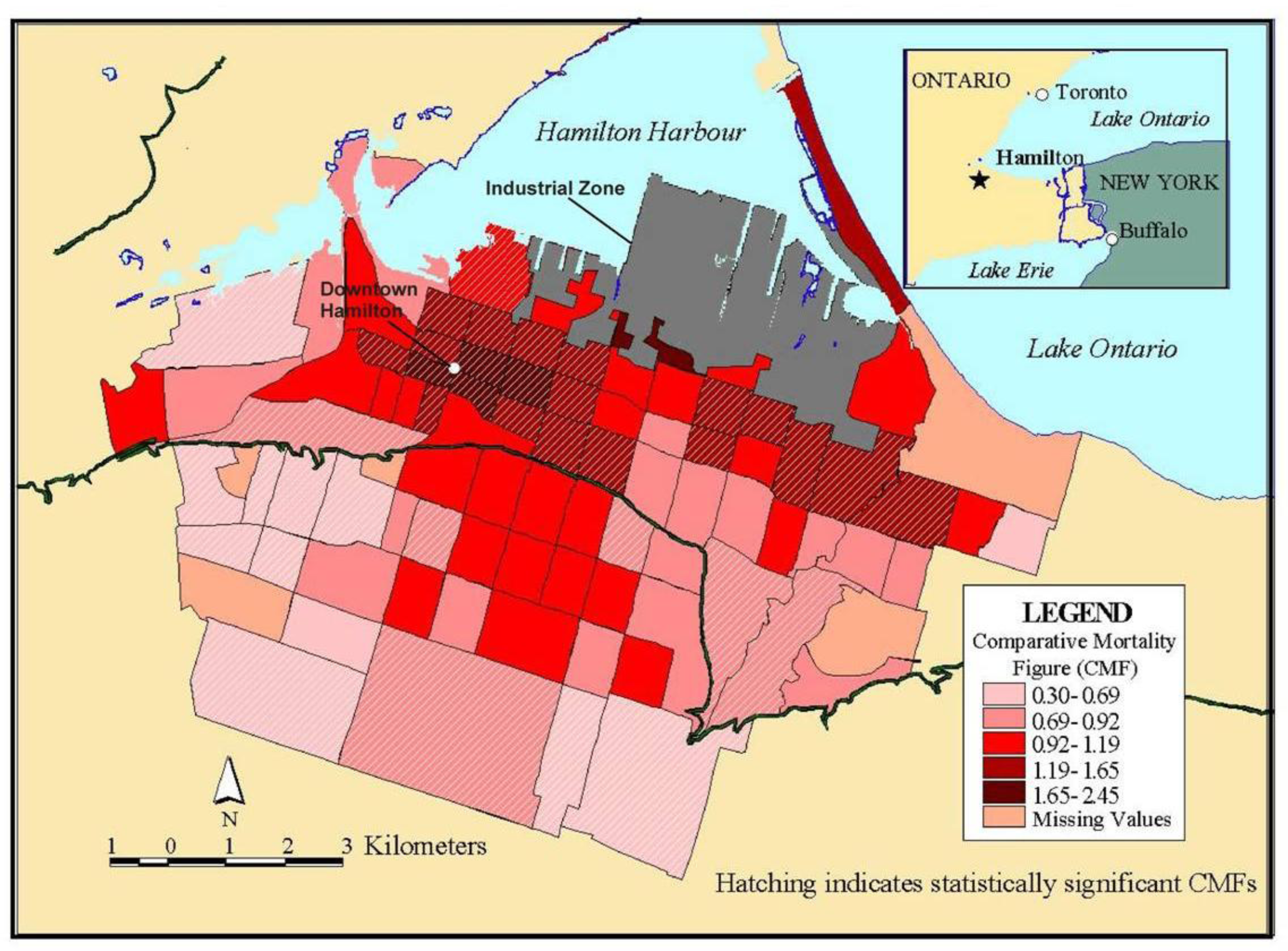
Figure 10 shows a map for women aged 20−24 years in Hamilton randomly selected as part of a respiratory survey of some 3,300 adults of both sexes in this age group in the city. As is evident on the map, there appears to be an association between higher asthma rates and proximity to a major industrial area that emits particulate air pollution.
In both examples above, we explored “first order” intensity or the tendency of some areas to display a higher density of point cases. Other point pattern analyses like Ripley’s K function seek to assess “second order” effects that measure spatial interaction between the points at various distances [
13]. These tests can be useful for testing hypotheses about infectious disease transmission, and as discussed next, more advanced models can include a temporal component.
Spatial Correlation and Regression
A final type of modeling deals with spatial association or correlation between two or more attribute values at the same location. For example, we may wish to predict mortality rates in given areas with other attribute data such as socioeconomic, lifestyle, and pollution exposure variables. This approach then becomes similar to regression analysis (see, e.g., [
19,
26]). Predicting health outcomes from environmental exposure while controlling for other known risk factors leads to suggestive evidence of statistical (and potentially causal) associations. When epidemiologic investigations use health data from contiguous or nearby geographic areas, the data may not provide independent estimates of the dependent variable (e.g., relative risk of mortality). If we account for this lack of independence with covariates that are also spatially autocorrelated in a similar way, then bias and underestimation of statistical variability should be reduced because the error terms from such a model tend to be uncorrelated. If areas differ, however, in some unmeasured or unsuspected way that affects mortality, residuals are likely to be autocorrelated [
27]. Careful examination and mapping of the residuals can also suggest geographic locations where the model fails to predict mortality accurately, and this may provide clues as to which factors explain some of the variation in mortality or morbidity. When autocorrelation in the residuals cannot be eliminated by adding new variables or changing the specification of the model, other techniques can be employed to avoid bias and inflated significance levels (see [
28,
29] for detailed conceptual and mathematical expositions of methods for dealing with autocorrelated residuals). Usually these techniques involve either filtering the spatial autocorrelation out of the model beforehand and running the filtered variables through ordinary or weighted least squares [
19,
30]; alternatively, autocorrelation can be built into the error term of the model, known generally as the “autoregressive” model [
11]. The latter model has many forms, but the most common one is called a simultaneous autoregressive (SAR) model.
In another recent study, Jerrett
et al. [
2] investigated the effects of particulate air pollution on mortality in Los Angeles, CA.
Figure 11 shows the prediction surface from a land use regression model [
31].
The researchers found large significant associations between particulate air pollution and mortality, with especially elevated risks for ischemic heart disease. Risks using this intra-urban exposure assessment were more than two times greater than shown in earlier studies that were based on central monitoring data and used exposure contrasts between cities rather than within them.
Importantly, the researchers were able to examine the residual mortality spatially through multilevel modeling. Figures below show the residual mortality pattern present when only the individual risks are included in the model with no pollution term (
Figure 12), and the effect including pollution (
Figure 13). There is a substantial reduction in residual mortality when pollution is included in the model. Further analyses in
Figure 14 show how inclusion of a term measuring proximity to major freeways further reduced the residual mortality. Statistical tests confirmed significant reductions in residual mortality were associated with pollution, suggesting convincingly that pollution was associated positively with mortality.
These recent methodological advances, with the use of sophisticated Bayesian methods and with multilevel analyses, represent a major new direction in the field. In both instances, confidence in the observed health effects increased substantially with the examination of residual spatial patterns in the data. Removal of these patterns with inclusion of the environmental pollution variables provided stronger evidence that the associations did not occur by chance.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















