A Novel Approach for the Detection of Standing Tree Stems from Plot-Level Terrestrial Laser Scanning Data

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Terrestrial Laser Scanning Data
2.2. The Reference Data for Validation
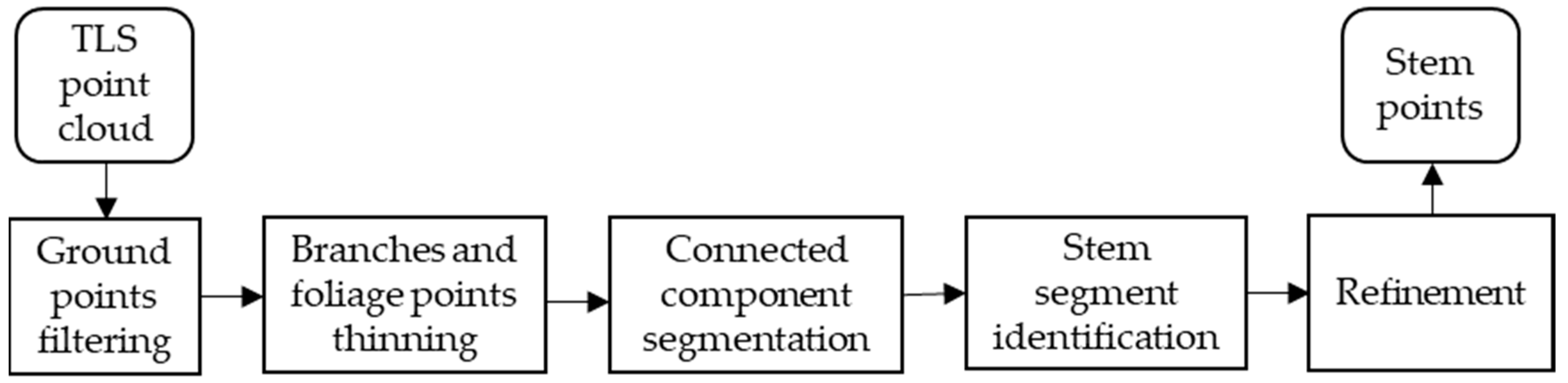
2.3. Tree Stem Point Extraction
2.3.1. Ground Filtering
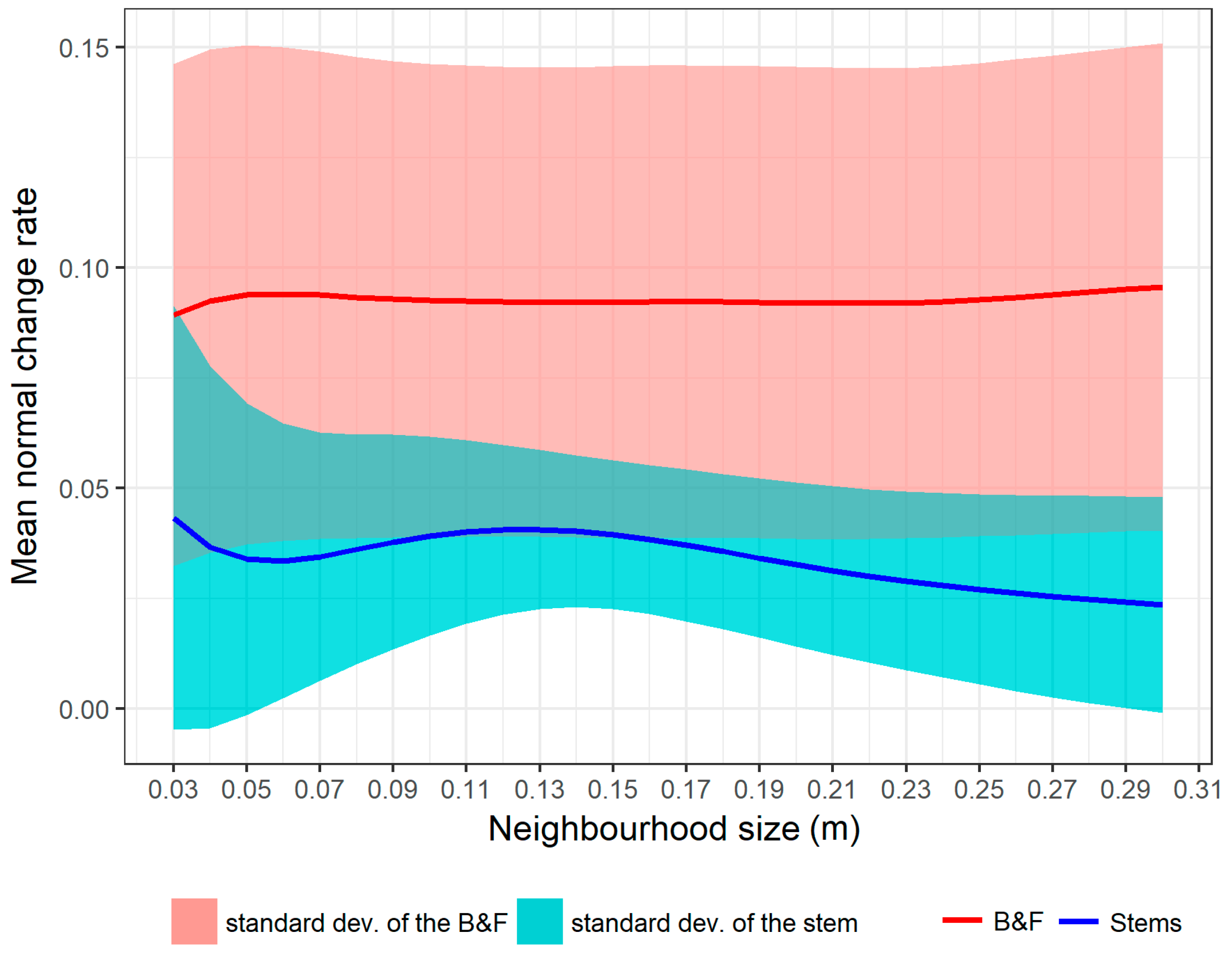
2.3.2. Branches and Foliage Points Thinning Based on Curvature Feature
2.3.3. Segment-Based Stem Point Identification
Connected Component Segmentation
Segment Filtering by the Number of Points Per Segment
Stem Segment Extraction Based on the Height-To-Width Ratio
2.3.4. Refinement of Extracted Stem Points
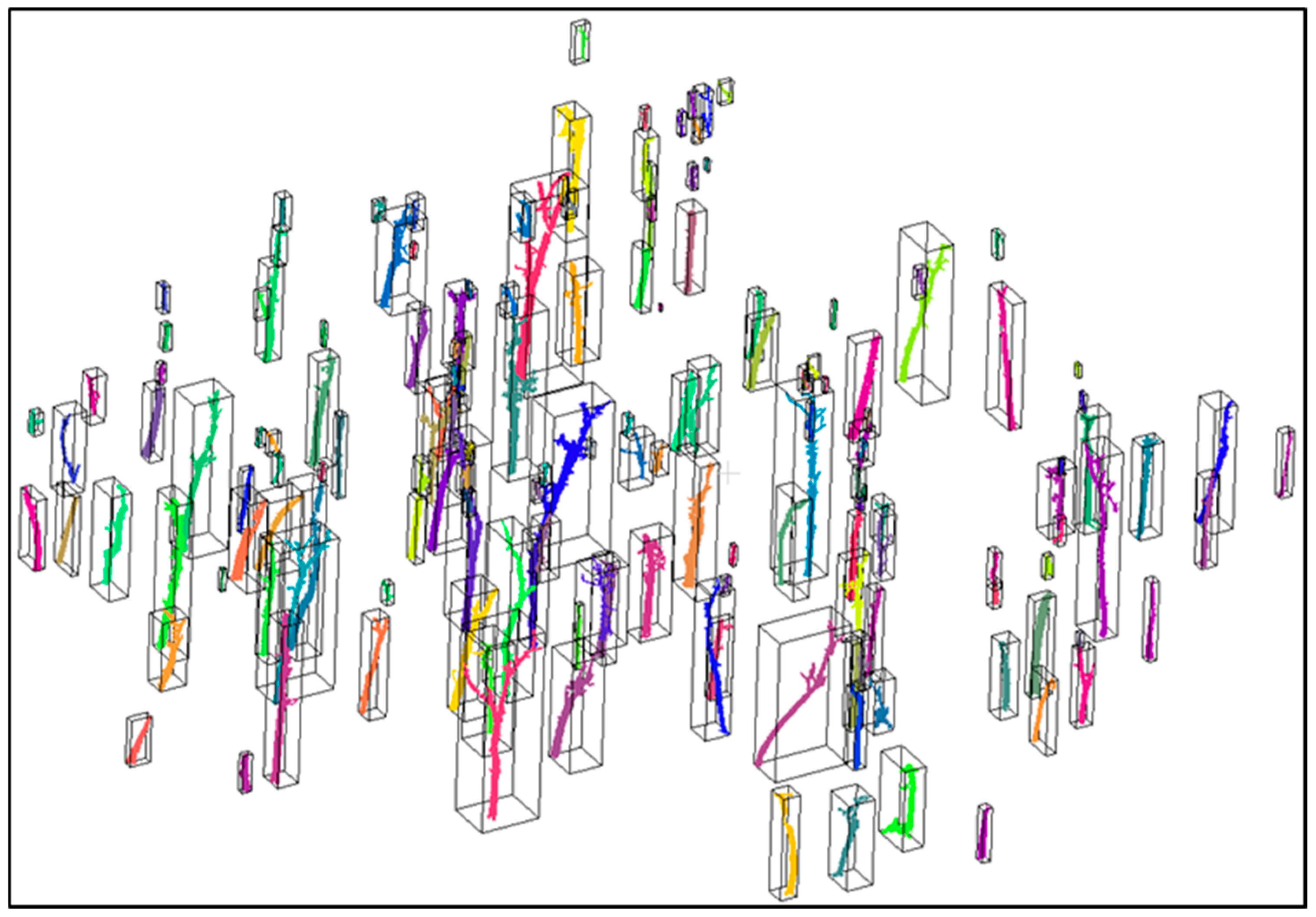
2.4. Segmentation of Individual Stems and Stem Mapping
2.5. Methods of Accuracy Evaluation
3. Results
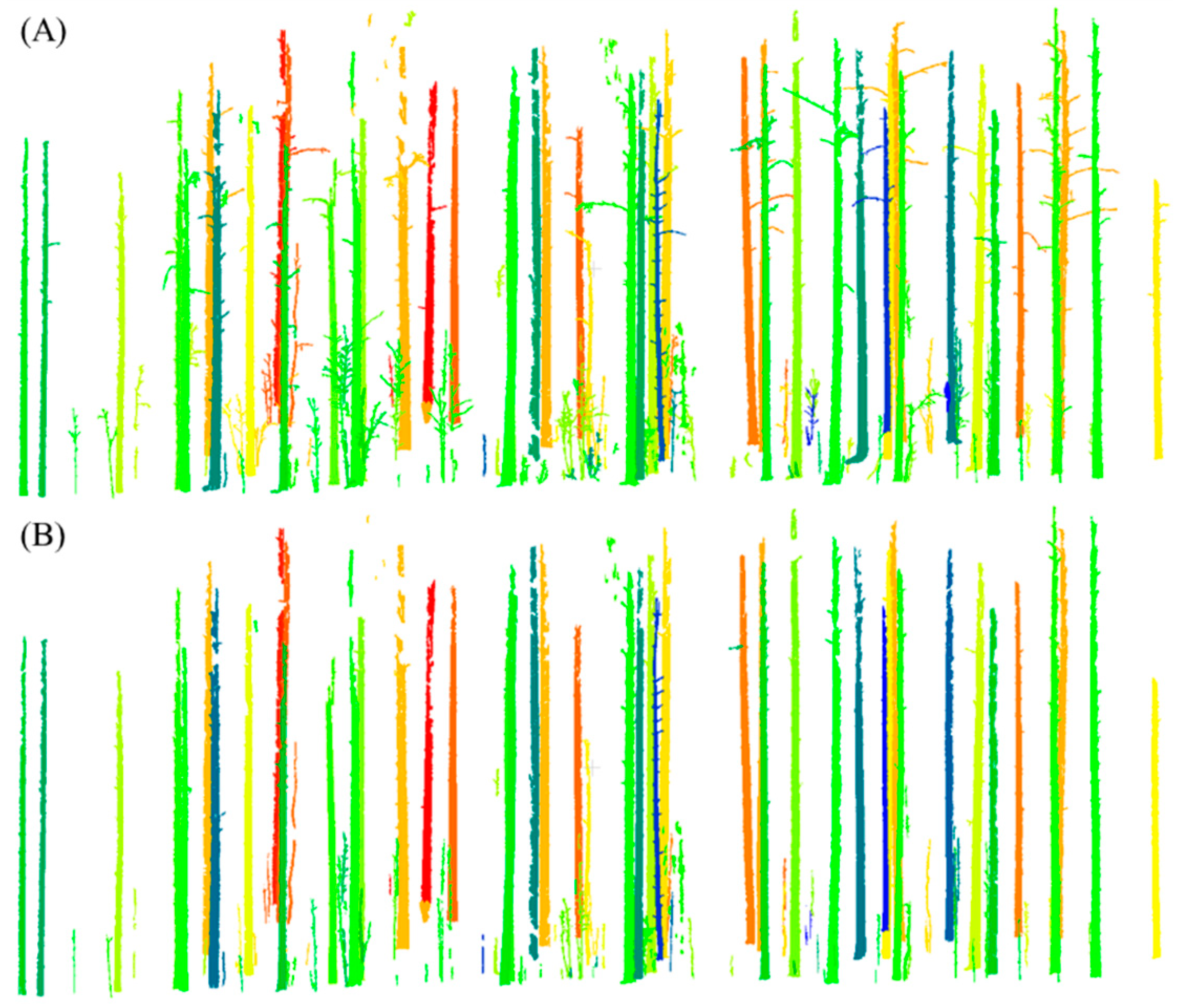
3.1. The Accuracy of Stem Point Extraction
3.2. The Accuracy of Stem Mapping
4. Discussion
4.1. Stem Detection Accuracy
4.2. Applicability to Various Stem Forms
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kindermann, G.; McCallum, I.; Fritz, S.; Obersteiner, M. A global forest growing stock, biomass and carbon map based on FAO statistics. Silva Fenn. 2008, 42, 387–396. [Google Scholar] [CrossRef]
- Houghton, R.A. Aboveground forest biomass and the global carbon balance. Glob. Chang. Biol. 2005, 11, 945–958. [Google Scholar] [CrossRef]
- Milena, S.; Markku, K. Allometric Models for Tree Volume and Total Aboveground Biomass in a Tropical Humid Forest in Costa Rica1. Biotropica 2005, 37, 2–8. [Google Scholar] [CrossRef]
- West, P.W. Trees and Forest Measurement; Springer: Berlin/Heidelberg, Germany, 2009; ISBN 9783540959656. [Google Scholar]
- Kankare, V.; Holopainen, M.; Vastaranta, M.; Puttonen, E.; Yu, X.; Hyyppä, J.; Vaaja, M.; Hyyppä, H.; Alho, P. Individual tree biomass estimation using terrestrial laser scanning. ISPRS J. Photogramm. Remote Sens. 2013, 75, 64–75. [Google Scholar] [CrossRef]
- Stovall, A.E.L.; Vorster, A.G.; Anderson, R.S.; Evangelista, P.H.; Shugart, H.H. Non-destructive aboveground biomass estimation of coniferous trees using terrestrial LiDAR. Remote Sens. Environ. 2017, 200, 31–42. [Google Scholar] [CrossRef]
- Burkhart, H.E.; Tomé, M. Modeling Forest Trees and Stands; Springer: Dordrecht, The Netherlands, 2012; ISBN 9048131707. [Google Scholar]
- Liang, X.; Kankare, V.; Hyyppä, J.; Wang, Y.; Kukko, A.; Haggrén, H.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Guan, F.; et al. Terrestrial laser scanning in forest inventories. ISPRS J. Photogramm. Remote Sens. 2016, 115, 63–77. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Litkey, P.; Hyyppa, J.; Kaartinen, H.; Vastaranta, M.; Holopainen, M. Automatic Stem Mapping Using Single-Scan Terrestrial Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2012, 50, 661–670. [Google Scholar] [CrossRef]
- Lindberg, E.; Holmgren, J.; Olofsson, K.; Olsson, H. Estimation of stem attributes using a combination of terrestrial and airborne laser scanning. Eur. J. For. Res. 2012, 131, 1917–1931. [Google Scholar] [CrossRef] [Green Version]
- Maas, H.G.; Bienert, A.; Scheller, S.; Keane, E. Automatic forest inventory parameter determination from terrestrial laser scanner data. Int. J. Remote Sens. 2008, 29, 1579–1593. [Google Scholar] [CrossRef]
- Tansey, K.; Selmes, N.; Anstee, A.; Tate, N.J.; Denniss, A. Estimating tree and stand variables in a Corsican Pine woodland from terrestrial laser scanner data. Int. J. Remote Sens. 2009, 30, 5195–5209. [Google Scholar] [CrossRef]
- Wang, D.; Hollaus, M.; Puttonen, E.; Pfeifer, N. Automatic and Self-Adaptive Stem Reconstruction in Landslide-Affected Forests. Remote Sens. 2016, 8, 974. [Google Scholar] [CrossRef]
- Lefsky, M.A.; McHale, M.R. Volume estimates of trees with complex architecture from terrestrial laser scanning. J. Appl. Remote Sens. 2008, 2, 23519–23521. [Google Scholar]
- Aschoff, T.; Thies, M.; Spiecker, H. Describing forest stands using terrestrial laser-scanning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 35, 237–241. [Google Scholar]
- Hopkinson, C.; Chasmer, L.; Young-Pow, C.; Treitz, P. Assessing forest metrics with a ground-based scanning lidar. Can. J. For. Res. 2004, 34, 573–583. [Google Scholar] [CrossRef]
- Olofsson, K.; Holmgren, J.; Olsson, H. Tree Stem and Height Measurements using Terrestrial Laser Scanning and the RANSAC Algorithm. Remote Sens. 2014, 6, 4323–4344. [Google Scholar] [CrossRef] [Green Version]
- Côté, J.-F.; Widlowski, J.-L.; Fournier, R.A.; Verstraete, M.M. The structural and radiative consistency of three-dimensional tree reconstructions from terrestrial lidar. Remote Sens. Environ. 2009, 113, 1067–1081. [Google Scholar] [CrossRef] [Green Version]
- Kukko, A.; Kaasalainen, S.; Litkey, P. Effect of incidence angle on laser scanner intensity and surface data. Appl. Opt. 2008, 47, 986–992. [Google Scholar] [CrossRef] [PubMed]
- Pfeifer, N.; Dorninger, P.; Haring, A.; Fan, H. Investigating terrestrial laser scanning intensity data: Quality and functional relations. In Proceedings of the International Conference Optical 3-D Measurement Techniques VIII, Zürich, Switzerland, 9–12 July 2007. [Google Scholar]
- Pesci, A.; Teza, G. Effects of surface irregularities on intensity data from laser scanning: An experimental approach. Ann. Geophys. 2008, 51, 839–848. [Google Scholar]
- Kaasalainen, S.; Krooks, A.; Kukko, A.; Kaartinen, H. Radiometric Calibration of Terrestrial Laser Scanners with External Reference Targets. Remote Sens. 2009, 1, 144–158. [Google Scholar] [CrossRef] [Green Version]
- Danson, F.M.; Gaulton, R.; Armitage, R.P.; Disney, M.; Gunawan, O.; Lewis, P.; Pearson, G.; Ramirez, A.F. Developing a dual-wavelength full-waveform terrestrial laser scanner to characterize forest canopy structure. Agric. For. Meteorol. 2014, 198, 7–14. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Douglas, E.; Strahler, A.; Schaaf, C.; Yang, X.; Wang, Z.; Yao, T.; Zhao, F.; Saenz, E.J.; Paynter, I. Separating leaves from trunks and branches with dual-wavelength terrestrial LiDAR scanning. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Melbourne, VIC, Australia, 21–26 July 2013; pp. 3383–3386. [Google Scholar]
- Kelbe, D.; van Aardt, J.; Romanczyk, P.; van Leeuwen, M.; Cawse-Nicholson, K. Single-Scan Stem Reconstruction Using Low-Resolution Terrestrial Laser Scanner Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3414–3427. [Google Scholar] [CrossRef]
- Liang, X.; Kankare, V.; Yu, X.; Hyyppä, J.; Holopainen, M. Automated Stem Curve Measurement Using Terrestrial Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1739–1748. [Google Scholar] [CrossRef]
- Lalonde, J.F.; Vandapel, N.; Huber, D.F.; Hebert, M. Natural terrain classification using three-dimensional ladar data for ground robot mobility. J. Field Robot. 2006, 23, 839–861. [Google Scholar] [CrossRef]
- Ma, L.; Zheng, G.; Eitel, J.U.H.; Magney, T.S.; Moskal, L.M. Determining woody-to-total area ratio using terrestrial laser scanning (TLS). Agric. For. Meteorol. 2016, 228–229, 217–228. [Google Scholar] [CrossRef]
- Brodu, N.; Lague, D. 3D terrestrial lidar data classification of complex natural scenes using a multi-scale dimensionality criterion: Applications in geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Xia, S.; Wang, C.; Pan, F.; Xi, X.; Zeng, H.; Liu, H. Detecting stems in dense and homogeneous forest using single-scan TLS. Forests 2015, 6, 3923–3945. [Google Scholar] [CrossRef]
- Zhu, X.; Skidmore, A.K.; Darvishzadeh, R.; Niemann, K.O.; Liu, J.; Shi, Y.; Wang, T. Foliar and woody materials discriminated using terrestrial LiDAR in a mixed natural forest. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 43–50. [Google Scholar] [CrossRef]
- Chen, M.; Wan, Y.; Wang, M.; Xu, J. Automatic Stem Detection in Terrestrial Laser Scanning Data With Distance-Adaptive Search Radius. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2968–2979. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Ning, X. SVM-based classification of segmented airborne LiDAR point clouds in urban areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Vosselman, G. Point cloud segmentation for urban scene classification. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 1, 257–262. [Google Scholar] [CrossRef]
- Trevor, A.J.B.; Gedikli, S.; Rusu, R.B.; Christensen, H.I. Efficient organized point cloud segmentation with connected components. Semant. Percept. Mapp. Explor. 2013. Available online: https://cs.gmu.edu/~kosecka/ICRA2013/spme13_trevor.pdf (accessed on 16 October 2018).
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef] [Green Version]
- Vo, A.-V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Polewski, P.; Yao, W.; Heurich, M.; Krzystek, P.; Stilla, U. A voting-based statistical cylinder detection framework applied to fallen tree mapping in terrestrial laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 129, 118–130. [Google Scholar] [CrossRef]
- Amiri, N.; Polewski, P.; Yao, W.; Krzystek, P.; Skidmore, A. Detection of single tree stems in forested areas from high density ALS point clouds using 3D shape descriptors. ISPRS Ann. Photogram. Remote Sens. Spat. Inform. Sci. 2017, IV-2/W4, 35–42. [Google Scholar] [CrossRef]
- Olofsson, K.; Holmgren, J. Single Tree Stem Profile Detection Using Terrestrial Laser Scanner Data, Flatness Saliency Features and Curvature Properties. Forests 2016, 7, 207. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J.; Kaartinen, H.; Lehtomäki, M.; Pyörälä, J.; Pfeifer, N.; Holopainen, M.; Brolly, G.; Francesco, P.; Hackenberg, J.; et al. International benchmarking of terrestrial laser scanning approaches for forest inventories. ISPRS J. Photogramm. Remote Sens. 2018, 144, 137–179. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Girardeau-Montaut, D. CloudCompare—3D Point Cloud and Mesh Processing Software (Version 2.10.beta). GPL Softw. 2018. Available online: http://www.cloudcompare.org/ (accessed on 16 October 2018).
- Pauly, M.; Gross, M.; Kobbelt, L.P. Efficient simplification of point-sampled surfaces. In Proceedings of the Conference on Visualization ’02, Boston, MA, USA, 27 October–1 November 2002; IEEE Computer Society: Washington, DC, USA, 2002; pp. 163–170. [Google Scholar]
- Lin, C.-H.; Chen, J.-Y.; Su, P.-L.; Chen, C.-H. Eigen-feature analysis of weighted covariance matrices for LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2014, 94, 70–79. [Google Scholar] [CrossRef]
- Nurunnabi, A.; West, G.; Belton, D. Outlier detection and robust normal-curvature estimation in mobile laser scanning 3D point cloud data. Pattern Recognit. 2015, 48, 1404–1419. [Google Scholar] [CrossRef]
- Jin, S.; Tamura, M.; Susaki, J. A new approach to retrieve leaf normal distribution using terrestrial laser scanners. J. For. Res. 2016, 27, 631–638. [Google Scholar] [CrossRef]
- Ma, L.; Zheng, G.; Eitel, J.U.H.; Moskal, L.M.; He, W.; Huang, H. Improved Salient Feature-Based Approach for Automatically Separating Photosynthetic and Nonphotosynthetic Components Within Terrestrial Lidar Point Cloud Data of Forest Canopies. IEEE Trans. Geosci. Remote Sens. 2016, 54, 679–696. [Google Scholar] [CrossRef]
- Vosselman, G.; Gorte, B.G.H.; Sithole, G.; Rabbani, T. Recognising structure in laser scanner point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 46, 33–38. [Google Scholar]
- Xu, L.; Oja, E. Randomized Hough transform (RHT): Basic mechanisms, algorithms, and computational complexities. CVGIP Image Underst. 1993, 57, 131–154. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot ID | Complexity Categories | Stem Density (stems/ha) | DBH (cm) | Tree Height (m) | Point Population (million) | |
|---|---|---|---|---|---|---|
| Single-Scan | Multi-Scan | |||||
| 1 | Easy | 498 | 22.8 ± 6.6 | 18.7 ± 3.9 | 23.6 | 111 |
| 2 | Easy | 820 | 16.0 ± 6.9 | 13.7 ± 4.0 | 23.6 | 114 |
| 3 | Medium | 1445 | 14.8 ± 7.4 | 15.5 ± 6.8 | 23.7 | 120 |
| 4 | Medium | 762 | 19.6 ± 14.1 | 16.1 ± 10.2 | 27.4 | 129 |
| 5 | Difficult | 1279 | 14.3 ± 13.2 | 13.0 ± 7.0 | 23.7 | 125 |
| 6 | Difficult | 2304 | 12.3 ± 5.5 | 13.0 ± 6.3 | 22.7 | 111 |
| 7 | Easy | 366 | 28.1 ± 7.5 | 12.7 ± 3.4 | - | 128 |
| Plot ID | Multi-Scan | Single-Scan | ||||||
|---|---|---|---|---|---|---|---|---|
| T.I(%) | T.II(%) | T.E.(%) | T.A.(%) | T.I(%) | T.II(%) | T.E.(%) | T.A.(%) | |
| 1 | 5.54 | 2.87 | 3.46 | 96.54 | 4.86 | 4.62 | 4.77 | 95.23 |
| 2 | 7.97 | 3.03 | 3.96 | 96.04 | 10.68 | 0.79 | 2.43 | 97.57 |
| 3 | 2.28 | 5.04 | 4.18 | 95.82 | 2.82 | 8.44 | 6.68 | 93.32 |
| 4 | 2.19 | 4.87 | 3.85 | 96.15 | 2.45 | 5.91 | 4.17 | 95.83 |
| 5 | 10.64 | 2.08 | 3.19 | 96.81 | 3.44 | 0.38 | 1.03 | 98.97 |
| 6 | 12.83 | 2.96 | 4.38 | 95.62 | 10.72 | 4.96 | 6.08 | 93.92 |
| 7 | 6.49 | 2.42 | 2.92 | 97.08 | - | - | - | - |
| Mean | 6.85 | 3.32 | 3.71 | 96.29 | 5.83 | 4.18 | 4.19 | 95.81 |
| Std.Dev | 4.00 | 1.16 | 0.53 | 0.53 | 3.87 | 3.10 | 2.16 | 2.16 |
| Scan Mode | Plot ID | Complexity Categories | Stem Detection | Location | DBH | ||||
|---|---|---|---|---|---|---|---|---|---|
| Completeness (%) | Correctness (%) | Mean Accuracy (%) | RMSE (cm) | Bias (cm) | RMSE (cm) | Bias (cm) | |||
| Multi-Scan | 1 | Easy | 86.27 | 97.78 | 91.67 | 0.90 | 0.73 | 1.60 | −0.57 |
| 2 | Easy | 82.14 | 95.83 | 88.46 | 2.40 | 1.20 | 2.16 | −1.11 | |
| 3 | Medium | 61.49 | 100.00 | 76.15 | 3.57 | 2.64 | 2.98 | −1.8 | |
| 4 | Medium | 57.69 | 97.83 | 72.58 | 3.52 | 1.58 | 2.4 | −0.97 | |
| 5 | Difficult | 45.80 | 93.75 | 61.54 | 5.12 | 3.21 | 3.02 | −1.87 | |
| 6 | Difficult | 26.27 | 98.41 | 41.47 | 6.21 | 3.93 | 3.85 | −2.21 | |
| Mean | 59.94 | 97.27 | 71.98 | 3.62 | 2.22 | 2.67 | −1.42 | ||
| Single-Scan | 1 | Easy | 80.39 | 97.62 | 88.17 | 7.10 | 5.10 | 4.20 | −1.96 |
| 2 | Easy | 57.14 | 92.31 | 70.59 | 3.20 | 2.15 | 3.19 | −1.82 | |
| 3 | Medium | 46.62 | 100.00 | 63.59 | 6.86 | 5.45 | 4.43 | −3.67 | |
| 4 | Medium | 34.62 | 100.00 | 51.43 | 3.07 | 1.97 | 3.69 | −2.46 | |
| 5 | Difficult | 13.74 | 90.00 | 23.84 | 5.00 | 4.34 | 4.37 | −3.30 | |
| 6 | Difficult | 8.47 | 100.00 | 15.63 | 7.68 | 5.72 | 4.71 | −3.86 | |
| Mean | 40.16 | 96.65 | 52.21 | 5.49 | 4.12 | 4.10 | −2.85 | ||
| Complexity Categories | Benchmarking Methods | Our Method | ||
|---|---|---|---|---|
| Single-Scan | Multi-Scan | Single-Scan | Multi-Scan | |
| Easy | 75% | 80% | 79% | 90% |
| Medium | 64% | 74% | 58% | 74% |
| Difficult | 31% | 53% | 20% | 52% |
| Complexity Categories | Benchmarking Methods | Our Method | ||
|---|---|---|---|---|
| Single-Scan | Multi-Scan | Single-Scan | Multi-Scan | |
| Easy | 5 cm | 3 cm | 7.1 cm | 2.4 cm |
| Medium | 8 cm | 5 cm | 6.9 cm | 3.6 cm |
| Difficult | 10 cm | 9 cm | 7.7 cm | 6.2 cm |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Wan, P.; Wang, T.; Cai, S.; Chen, Y.; Jin, X.; Yan, G. A Novel Approach for the Detection of Standing Tree Stems from Plot-Level Terrestrial Laser Scanning Data. Remote Sens. 2019, 11, 211. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11020211
Zhang W, Wan P, Wang T, Cai S, Chen Y, Jin X, Yan G. A Novel Approach for the Detection of Standing Tree Stems from Plot-Level Terrestrial Laser Scanning Data. Remote Sensing. 2019; 11(2):211. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11020211
Chicago/Turabian StyleZhang, Wuming, Peng Wan, Tiejun Wang, Shangshu Cai, Yiming Chen, Xiuliang Jin, and Guangjian Yan. 2019. "A Novel Approach for the Detection of Standing Tree Stems from Plot-Level Terrestrial Laser Scanning Data" Remote Sensing 11, no. 2: 211. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11020211